
Capturing downtime at the work request stage means logging the exact moment equipment stops functioning — before a technician is dispatched and before a repair begins. Most maintenance teams record downtime after the job is done, which introduces gaps, guesswork, and inaccurate timestamps that corrupt your downtime tracking data. Research from Aberdeen Group shows that companies with poor downtime visibility lose an average of $260,000 per hour of unplanned outage. Getting the start time right, at the point of the work request, is the first and most important step in fixing that problem.
This guide explains why the timing of downtime entry matters, what gets lost when you wait, and how a modern maintenance management system makes early capture automatic and accurate.
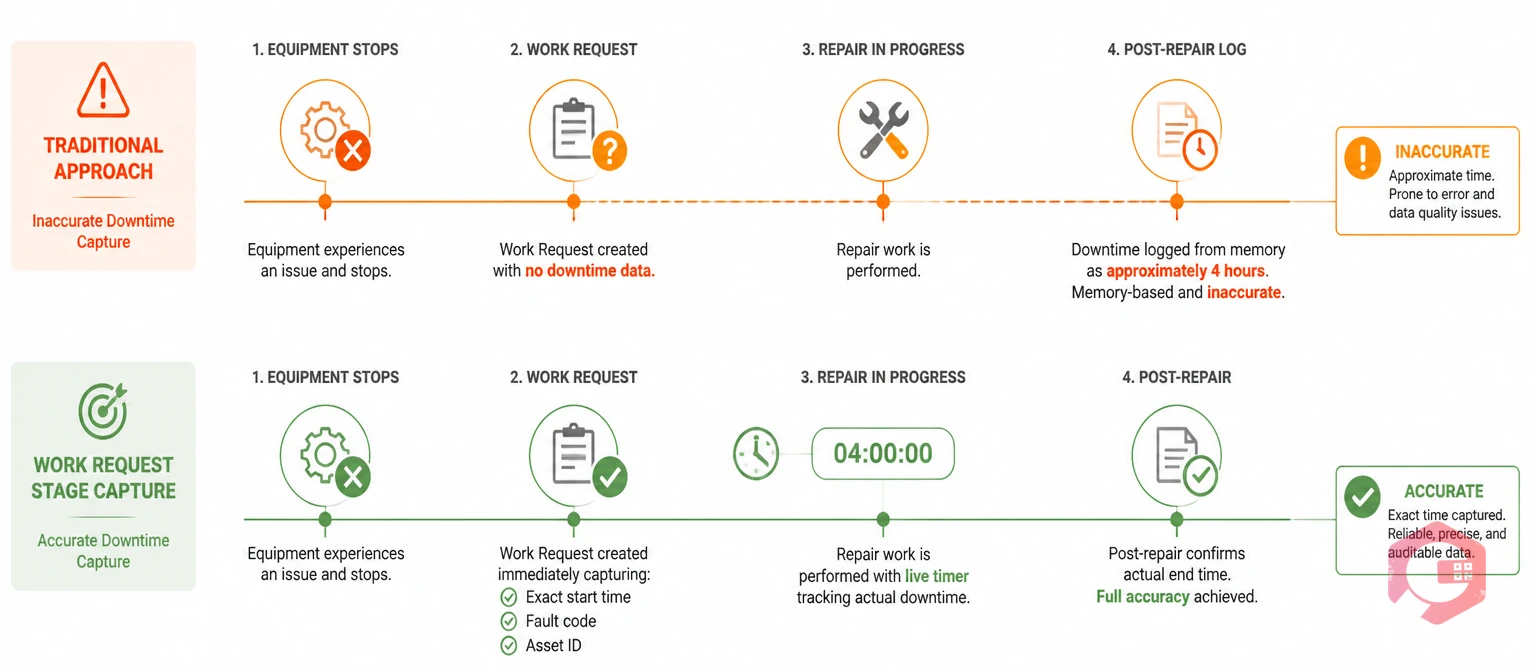
Work request-stage downtime capture is the practice of recording the downtime start time — and its reason — the moment a worker submits a fault report or work request. Instead of waiting for the technician to close the work order and fill in a downtime log afterward, the clock starts ticking the second someone raises the issue.
In a CMMS-driven workflow, this happens automatically. When an operator submits a work request via mobile app, QR code scan, or WhatsApp — the system timestamps it instantly. That timestamp becomes your downtime start time, tied directly to the asset, department, and failure category. No manual entry. No guesswork about "when did it actually stop?"
This approach aligns with how unplanned maintenance events actually happen in the field: the operator notices a problem and reports it. That moment is the true downtime start — not when the technician arrives, not when the repair finishes, and not when someone remembers to update the system two shifts later.
When technicians log downtime at the end of a job, three serious problems emerge that compound over time.
1. Inaccurate start times. Technicians often cannot recall exactly when the equipment failed. They note when they arrived on-site or when they started working — not when the asset actually stopped. This understates real downtime by anywhere from 30 minutes to several hours, depending on response delays and shift handovers.
2. Missing failure context. The person who first noticed the failure — the operator — is rarely consulted during post-repair data entry. Critical context like "machine was making noise for two days before it stopped" or "this is the third time this month" gets lost before it ever reaches your system.
3. Skipped entries under pressure. When backlogs are high, downtime logging is the first task to get skipped. A Plant Maintenance study found that up to 40% of unplanned downtime events in high-volume facilities go unlogged entirely when entry happens post-repair. That means your MTTR, MTBF, and availability metrics are built on an incomplete picture.
The result is a reporting cycle where management sees sanitized downtime numbers, makes decisions based on them, and then wonders why OEE targets keep slipping. The root issue is not strategy — it's the data entry gap built into the process itself.
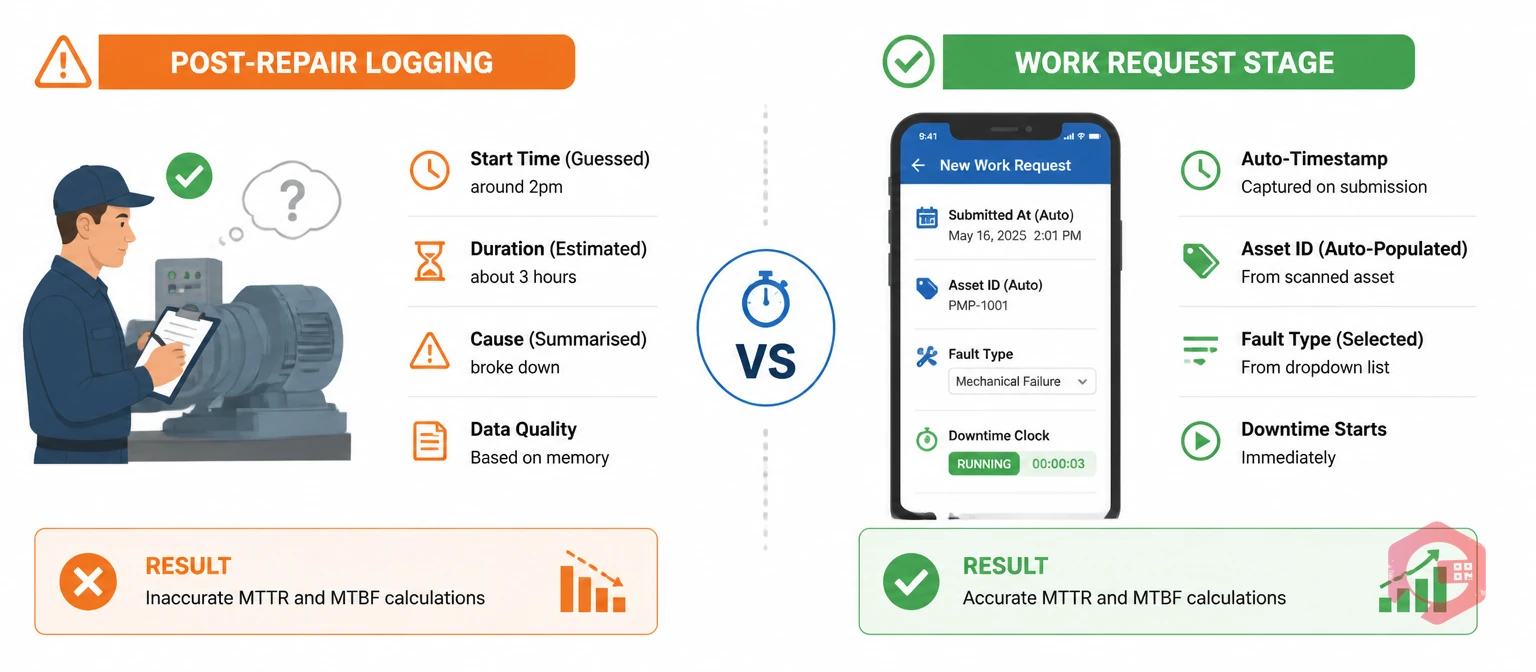
Here is a direct comparison of what each approach captures and what it misses:
| Criteria | Work Request-Stage Capture | Post-Repair Capture |
|---|---|---|
| Downtime start time | Exact — system-generated timestamp | Estimated — recalled by technician |
| Failure reason | Captured from operator at point of report | Captured from technician after repair — operator context lost |
| Data completeness | High — tied to asset, dept, shift automatically | Variable — depends on technician memory and time pressure |
| MTTR accuracy | Accurate — measures full response + repair time | Understated — often excludes response and wait time |
| MTBF reliability | High — consistent timestamps enable pattern detection | Low — missing events skew failure frequency calculations |
| Repeat failure detection | Automated — CMMS flags recurring asset issues | Manual — depends on someone noticing trends in reports |
| Skip/omission rate | Near zero — entry is part of raising the request | Up to 40% in high-pressure environments |
Mean Time to Repair (MTTR) measures how long it takes to restore equipment from the point of failure. Mean Time Between Failures (MTBF) measures how reliably equipment runs between breakdowns. Both metrics depend entirely on accurate start times for downtime events.
When downtime is logged at the work request stage, MTTR includes the full picture: the time between failure and the work request being raised, plus the response time, plus the actual repair. This is the number that matters for operational planning. A machine that breaks at 8:00 AM, gets reported at 8:15 AM, and is fixed by 10:00 AM has a real MTTR of two hours — not 1 hour and 45 minutes based on when the technician clocked in.
For MTBF, the difference is even more significant. Every missed or under-reported downtime event artificially extends the calculated interval between failures. If 3 out of 10 failures go unlogged — which happens regularly with post-repair entry — your MTBF looks 30% better than reality. That flawed number then informs maintenance scheduling, spare parts stocking, and capital investment decisions. All of them will be miscalibrated.
Teams using Cryotos report a 30% reduction in overall downtime after switching to real-time downtime capture tied to work requests — because for the first time, they can see their actual failure patterns and act on them.
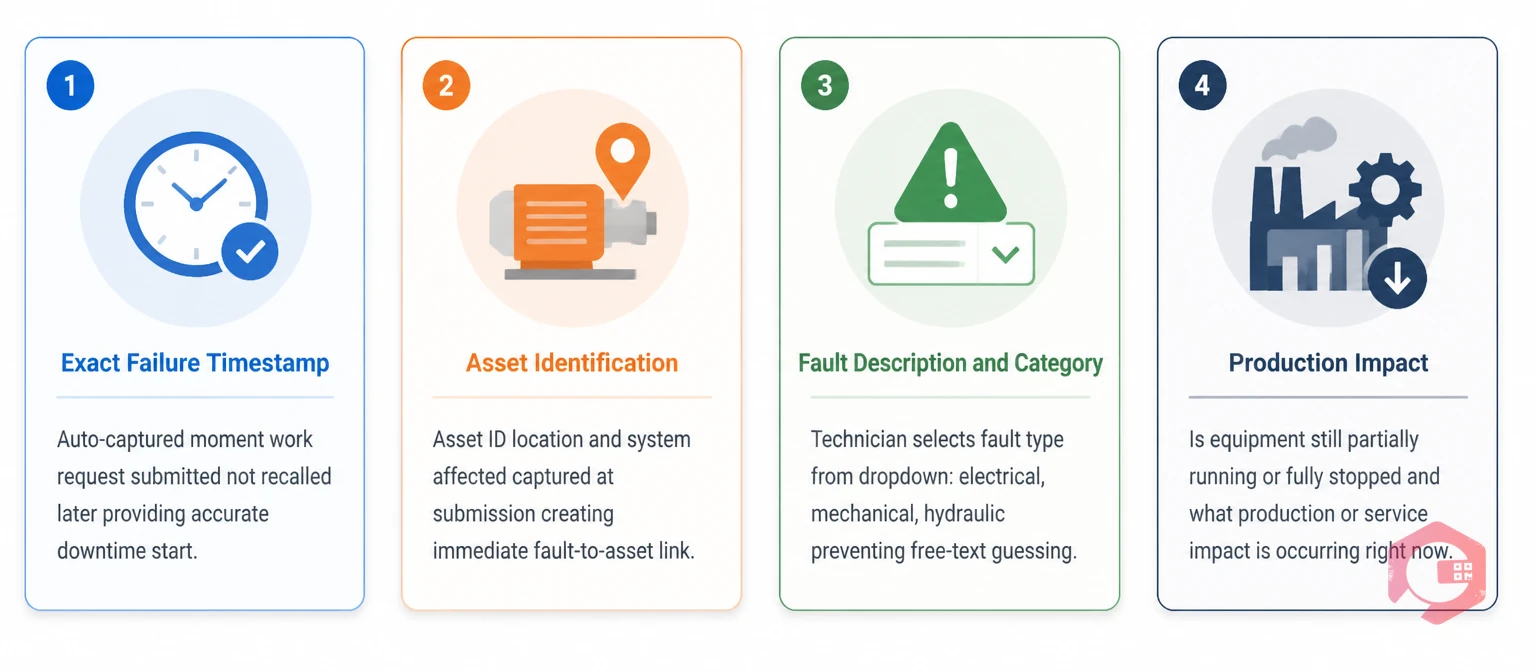
An effective work request-stage downtime entry should record the following minimum fields at the moment the request is submitted:
This six-field capture takes under 60 seconds via a mobile app or QR code scan on the asset. It requires no specialist knowledge from the operator — just an honest description of what they see. The rest — priority assignment, technician dispatch, and root cause analysis — flows from that initial clean data entry.
You can standardize what gets captured by building these fields into your work request templates directly, so every submission is structured the same way regardless of who raises it.
The biggest barrier to early downtime capture in manual or spreadsheet-based systems is that it adds steps. In a CMMS, those steps disappear — the system does the work automatically.
Here is how Cryotos handles it in practice. When an operator scans a QR code on an asset and submits a fault report, Cryotos records the exact timestamp, maps it to the asset record, logs it against the asset's downtime history, and creates a work order with the failure category pre-populated. The downtime tracking module starts the clock. When the technician marks the work order complete, the clock stops. MTTR is calculated automatically.
No one has to remember to log downtime. No one has to fill in a separate downtime form after the repair. The data flows directly from the work request into the BI dashboard, where maintenance managers can see downtime by asset, department, failure type, and shift — updated in real time.
For organizations running IoT sensors on critical equipment, the integration goes one step further. Sensors connected via SCADA or edge devices can trigger automatic work requests the moment a parameter breaches a threshold — before an operator even notices the problem. That gives you a downtime start time that predates human observation, which is as accurate as data gets.
According to McKinsey's operations research, manufacturers that automate maintenance data capture reduce unplanned downtime by 20–50% through faster response and earlier pattern detection.
While every maintenance operation benefits from accurate downtime data, the impact is highest in industries where production losses are immediate and measurable.
Manufacturing. A single line stoppage in automotive or food production can cost thousands per minute. Manufacturing maintenance teams need downtime data that is accurate enough to drive preventive scheduling decisions at the asset level — not just the plant level.
Food and Beverage. Regulatory compliance in food and beverage facilities requires documented equipment downtime for audits. Capturing it at the work request stage ensures the audit trail starts from the first reported symptom, not from when the technician got around to the paperwork.
Oil and Gas. In oil and gas operations, downtime events have safety, environmental, and financial implications that require complete incident records. A 15-minute gap in downtime reporting can create a compliance problem that far outweighs the cost of the repair itself.
Healthcare. Equipment downtime in hospitals affects patient care. Healthcare facility teams need to track not just how long equipment was down, but what the clinical impact was — and that context only exists at the point of the initial report, when the clinical staff first flag the issue.
MTTR measures the total time from equipment failure to restoration. If the start time is logged after the repair — based on technician memory — it typically reflects when work began, not when the failure occurred. Response time, waiting time, and any production impact before the technician arrived are all excluded. This understates real MTTR and makes your maintenance operation look faster than it is, which leads to under-resourcing response workflows.
Yes. Work request-stage capture only asks operators for what they directly observe: which machine, what they saw, and when. Technical analysis — failure categorization, root cause, corrective action — is handled by maintenance teams after the work order is created. Keeping the operator's role simple increases submission rates and data quality, because operators are not asked to diagnose problems they are not trained to diagnose.
Delayed operator reporting is a workflow and culture issue, not a technology one. The fix is to make reporting as fast and frictionless as possible — QR codes on every asset, mobile-first forms with dropdown failure categories, and WhatsApp-based reporting for operators who don't use apps. When reporting takes under 60 seconds, compliance rates increase significantly. Some organizations also post visual instructions at each machine showing exactly how to raise a work request.
Accurate downtime data feeds directly into failure pattern analysis. When every downtime event is logged from the moment it is reported, your CMMS builds a reliable history of when, how, and how often each asset fails. That history is the foundation for shifting from reactive to preventive maintenance scheduling — because you can see failure patterns clearly enough to act before the next failure occurs.
Yes. Planned downtime for scheduled maintenance, shutdowns, or calibration should also be logged at the work order creation stage — not retrospectively. Consistent logging of both planned and unplanned downtime gives you a complete picture of asset availability, which is the denominator in your OEE calculation. Without it, availability figures are overstated and OEE targets become meaningless benchmarks.
If your maintenance team is still logging downtime after the fact — filling in times from memory at the end of a shift — you are working with data that is systematically inaccurate. The fix is not more training or stricter checklists. It is moving the data entry point to the work request stage, where the information is fresh, context is complete, and the system can do most of the work automatically. Cryotos CMMS captures downtime from the first work request, connects it to asset history, and gives your team the accurate metrics they need to reduce failures before they happen. Start with a free demo and see what your real downtime numbers look like.



Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











