
Failure-finding maintenance is a proactive maintenance strategy used to detect hidden failures in assets that do not reveal themselves during normal operation. Unlike reactive or time-based maintenance, failure-finding maintenance specifically targets hidden-function assets — equipment like safety valves, fire alarms, and emergency shutdown systems that remain dormant until called upon during an emergency. According to OSHA's Process Safety Management guidelines, undetected failures in protective devices are a leading contributor to catastrophic industrial incidents. Studies from NFPA indicate that up to 30% of safety system failures go undetected for months before an incident triggers their discovery. Without a structured testing program, these assets appear fully functional while their protective capability has completely degraded.
Failure-finding maintenance (FFM) is defined within Reliability-Centered Maintenance (RCM) as a scheduled task designed to identify failures that have already occurred but are not yet evident during normal operation. The term was popularized by John Moubray in his foundational RCM work, where he described hidden-function failures as uniquely dangerous because they silently strip away a layer of protection without triggering any alarm or operational disruption.
The critical insight is this: a safety valve that fails to open at its set pressure doesn't stop the process from running — it just means the process is no longer protected. You won't know until an overpressure event occurs and the valve fails to respond. Failure-finding maintenance closes this dangerous gap through regular, deliberate testing.
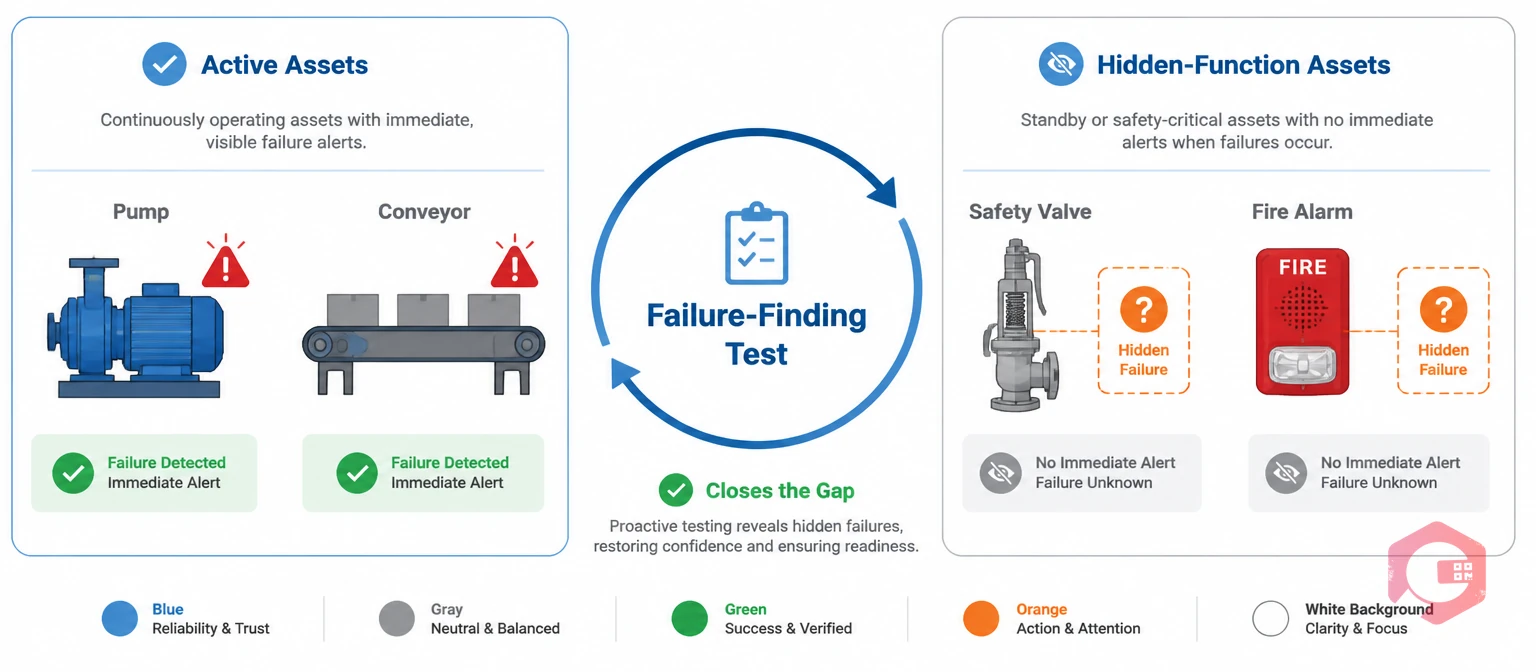
Active assets perform their function continuously. A pump moves fluid; a conveyor moves product. When an active asset fails, the failure is immediately obvious because the process stops. Hidden-function assets are different — their entire purpose is to respond during an abnormal event. A fire alarm doesn't need to sound when conditions are normal. A pressure relief valve doesn't need to open when system pressure is within range. Their dormancy is exactly why they require failure-finding maintenance: there's no natural feedback loop to reveal a developing fault.
Hidden failures create what RCM practitioners call a "multiple failure" risk. A hidden failure on its own may not cause harm. But when the protected asset also fails, the safety layer that should have activated is already compromised — and the consequence can be catastrophic. This is why regulatory bodies like the UK Health and Safety Executive (HSE) and standards like IEC 61511 for Safety Instrumented Systems mandate regular proof testing of protective devices. Failure-finding maintenance is the operational mechanism that satisfies these requirements.

Failure-finding maintenance applies to any asset whose function is protective or emergency-response in nature. Here are the most common categories found across industrial facilities.
Safety valves and pressure relief valves (PRVs) are designed to open automatically when system pressure exceeds a set point, venting excess pressure to prevent vessel or pipeline rupture. They are among the most critical hidden-function assets in oil and gas, chemical, and pharmaceutical facilities. A PRV that has corroded, stuck, or been incorrectly re-seated after a previous pop will not open at its design pressure — and because it doesn't need to open during normal operation, this failure can persist for years. Failure-finding tasks for PRVs typically involve bench testing (removing the valve and testing it on a dedicated test rig) or in-line lift testing at a controlled pressure.
Fire detectors, smoke sensors, heat detectors, and combustible gas sensors are all hidden-function assets. Their detector elements can drift, become fouled with dust or chemical deposits, or simply fail with no visible indication. Failure-finding maintenance for fire and gas systems involves injecting test gas into gas detectors, using heat guns or magnet wands on fire detectors, and verifying signal transmission all the way through to the control panel and the field response (e.g., activating suppression systems or closing fire dampers). Most fire codes and NFPA 72 standards require these tests at set intervals — typically annually for full functional tests.
Emergency shutdown systems (ESD) are control system layers that shut down process equipment in response to a hazardous condition — a high pressure, a high temperature, or a dangerous gas reading. ESD valves, solenoids, and interlocks are all dormant during normal operation and can suffer internal failures (valve seat erosion, solenoid coil failure, logic system drift) without any process impact. Testing these assets often requires partial stroke testing (moving the valve partway through its stroke to verify it's not stuck) or full functional tests during planned shutdowns.
Backup power systems — diesel generators and uninterruptible power supplies — are textbook hidden-function assets. They exist solely for emergencies. A generator that fails to start during a grid outage reveals a hidden failure at the worst possible moment. Failure-finding maintenance for backup power typically involves load bank testing (running the generator under a simulated electrical load to verify output capacity) and automatic transfer switch testing to confirm the switchover logic functions correctly.
Not all failure-finding tasks are the same. The method depends on the asset type, the failure mode being targeted, and whether the test can be conducted while the plant is running or only during a shutdown.
A full functional test verifies the complete protective function end-to-end. For a safety valve, that means confirming it lifts at its set pressure. For a fire alarm, it means confirming the detector responds to the appropriate stimulus and that the signal reaches the control panel and triggers the correct field response. Functional tests provide the highest confidence in the asset's protective capability but often require the asset to be taken out of service, which may require a process shutdown.
Partial stroke testing is an intermediate option used primarily for ESD valves. The valve is moved partway through its stroke — typically 10–30% of its full travel — to confirm it's not mechanically stuck. Partial stroke testing can often be done online without shutting down the process, but it does not verify the full range of the protective function. It's used between full functional tests to reduce the risk of hidden failure accumulating between scheduled test intervals.
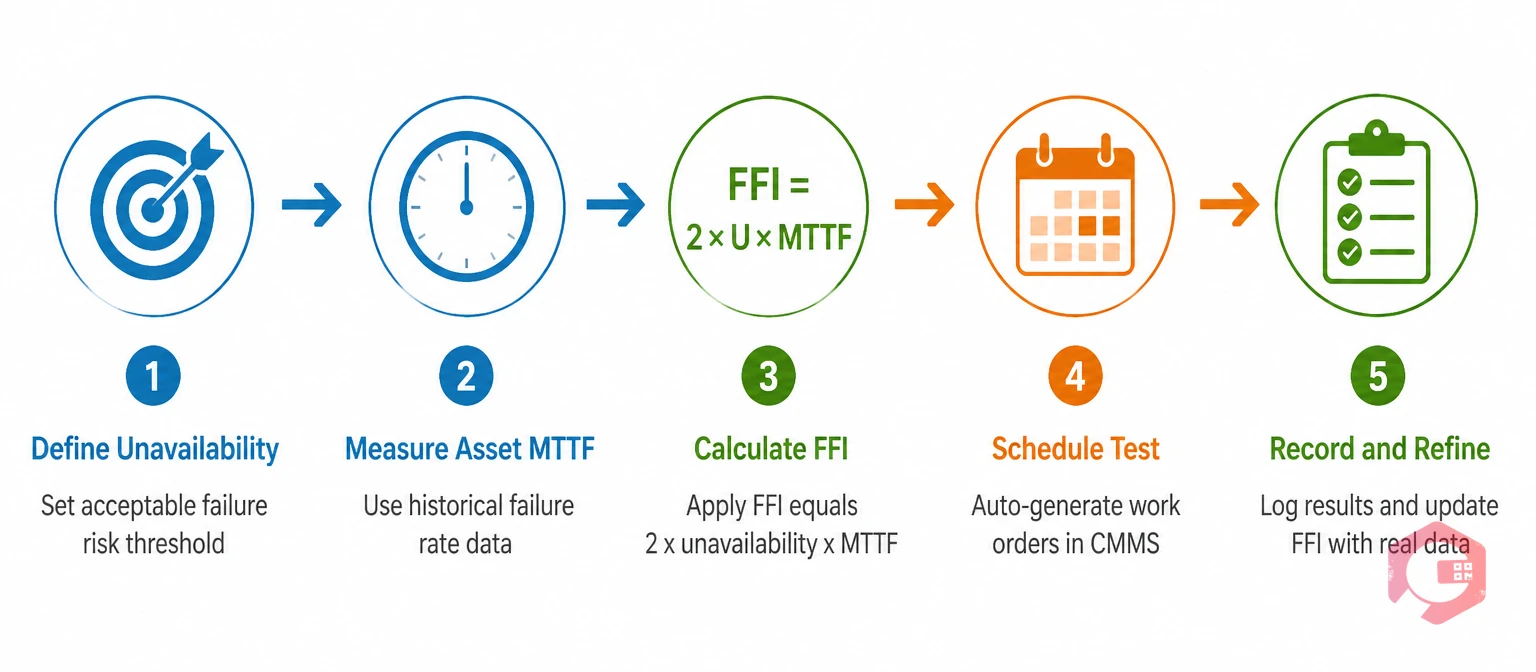
The Failure Finding Interval (FFI) is the time between successive failure-finding tests. Getting the FFI right is critical: test too infrequently and the probability of a hidden failure being present when you need the asset grows unacceptably high; test too frequently and you incur unnecessary maintenance costs and process disruption.
The standard RCM formula for calculating FFI is derived from the required availability of the protective function. If you need the protective device to be available at least 99% of the time it is demanded (i.e., a maximum unavailability of 1%), and the device has a mean time to failure (MTTF) of 10 years, the FFI is calculated as:
FFI = 2 × Target Unavailability × MTTF
Plugging in our example: FFI = 2 × 0.01 × 10 years = 0.2 years, or approximately every 10 weeks. This formula comes from Moubray's RCM II methodology and is accepted by standards bodies including IEC and API 581 for risk-based inspection. If your target unavailability is stricter (say, 0.1% for a high-hazard asset), your testing interval must be correspondingly shorter. A CMMS is the practical tool for tracking this FFI calculation per asset and generating work orders at the correct interval — more on that in the scheduling section below.
Testing a pressure relief valve requires careful preparation to avoid releasing hazardous materials and to ensure accurate results. Here is a typical failure-finding procedure for a spring-loaded PRV:
Testing fire and gas detection systems is a multi-layer process that confirms both the detection element and the downstream response are functional. Follow these steps for a thorough failure-finding inspection:
Failure-finding maintenance and preventive maintenance are both proactive — but they serve fundamentally different purposes and apply to different asset types. Confusing the two leads to either over-maintaining active assets or, more dangerously, under-maintaining hidden-function assets.
| Aspect | Failure-Finding Maintenance | Preventive Maintenance |
|---|---|---|
| Target Assets | Hidden-function (protective) assets — safety valves, alarms, ESD systems | Active assets that operate continuously — motors, pumps, conveyors |
| Purpose | Detect failures that have already occurred but are not yet evident | Prevent failures from occurring through scheduled servicing |
| Failure Visibility | Hidden — asset appears operational but protective function has failed | Evident — failure is immediately apparent when it occurs |
| Interval Basis | Calculated from required asset availability and MTTF (FFI formula) | Based on manufacturer recommendations, wear patterns, or usage hours |
| Test Method | Functional test, partial stroke test, injection of test stimulus | Lubrication, replacement of consumables, inspection, calibration |
| Outcome of Finding a Failure | Restores protective capability; records hidden failure for reliability analysis | Prevents an impending failure from causing downtime or damage |
| Regulatory Driver | Often mandatory — IEC 61511, API 527, NFPA 72, OSHA PSM | May be manufacturer-recommended or internally driven; less often mandated |
The biggest operational challenge in failure-finding maintenance is consistency. A safety valve that needs testing every 10 weeks across a facility with 200 PRVs, 150 fire detectors, and 80 ESD valves generates hundreds of precisely-timed work orders per year. Managing this in spreadsheets or on paper virtually guarantees missed intervals — which means hidden failures accumulate between tests, raising the probability that a protective device will fail to function when it is actually needed.
A Computerized Maintenance Management System (CMMS) solves this at scale. With Cryotos CMMS, you can set up each hidden-function asset with its calculated FFI, and the system automatically generates work orders at the correct interval. Technicians receive the work order on their mobile device, complete the test using a digital maintenance checklist that captures the as-found condition, test result, and any repairs made, and the work order is closed with a full audit trail.
Beyond scheduling, Cryotos provides several features that are particularly valuable for failure-finding programs. The asset tracking module maintains a complete test history for every hidden-function asset, giving you the data you need to refine FFI calculations as you accumulate real MTTF data from your facility. The BI dashboard lets reliability managers see, at a glance, which assets are overdue for testing, which have recurring failures, and what the overall availability of their protective device population looks like. When regulators or auditors ask for proof that your safety systems are being tested at required intervals, your complete digital records are available instantly — with no manual document retrieval.
Cryotos customers have reported 30% reductions in unplanned downtime and 25% improvements in maintenance efficiency after implementing structured PM and failure-finding programs through the platform. For sites with mandatory safety system testing requirements, the compliance assurance alone justifies the investment. Explore how Cryotos supports oil and gas maintenance — an industry where failure-finding maintenance is not optional.
Failure-finding maintenance is a type of scheduled test designed to check whether a safety or emergency asset — like a pressure relief valve or fire alarm — has already failed in a way that isn't visible during normal operation. The goal is to find hidden failures before they put people or processes at risk during an actual emergency.
The test interval for safety valves depends on their service conditions and the required availability of the protection they provide. As a starting point, API 510 and API 576 recommend testing at intervals of 3 to 10 years for most applications, with more frequent testing for valves in corrosive or fouling service. Facilities using the FFI formula from RCM can calculate a more precise interval based on their target unavailability and the valve's observed failure rate. A CMMS makes it practical to track individual valve intervals across large populations.
The Failure Finding Interval (FFI) is the calculated period between successive failure-finding tests for a hidden-function asset. It is derived from the RCM formula: FFI = 2 × Target Unavailability × MTTF. A shorter FFI increases confidence that the asset is functional when needed but increases maintenance cost and process disruption. The FFI should be reviewed periodically as real failure data accumulates from your facility's test records.
Preventive maintenance tries to prevent a failure from occurring — for example, replacing a bearing before it wears out. Failure-finding maintenance assumes a failure may have already occurred and schedules a test to find out. They apply to different types of assets: preventive maintenance targets active assets whose failures are immediately evident, while failure-finding maintenance targets hidden-function assets whose failures only become apparent during an emergency.
Any asset whose primary function is protective or emergency-response in nature may require failure-finding maintenance. Common examples include pressure relief valves, safety valves, fire and gas detectors, emergency shutdown valves, fire suppression systems, backup generators, UPS systems, and safety interlocks. The defining characteristic is that the asset does not perform any function during normal operations — it is only called upon when something goes wrong.
Managing failure-finding maintenance manually across a large facility is difficult and error-prone. Cryotos CMMS gives you the scheduling engine, digital checklists, and audit trail you need to run a compliant, consistent failure-finding program — across every hidden-function asset in your facility. Explore Cryotos CMMS and see how it can support your safety system testing requirements.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











