
Hidden failures and evident failures are the two primary failure categories in reliability-centered maintenance (RCM). An evident failure is one that operators notice immediately when it occurs, while a hidden failure goes undetected during normal operation — often until a secondary failure or a safety incident reveals it. Studies from the maintenance industry show that hidden failures account for up to 40% of all equipment failures in complex industrial systems, yet they receive far less proactive attention. If you're relying solely on reactive fixes for what you can see, you're leaving the most dangerous failures completely unmanaged.
An evident failure is any failure that is immediately obvious to the operator or maintenance team when it happens. A pump that stops running, a conveyor that jams, an alarm that triggers — these are evident. The machine is broken, and everyone knows it.
Because evident failures are visible, they naturally trigger an immediate response. The asset is taken offline, a work order is raised, and the repair begins. That visibility is actually their defining advantage: the failure mode is self-announcing, which means the window between failure and response is short.
While evident failures are disruptive and costly, they're at least on your radar. Your maintenance team can plan around them, set spare part stock levels, and train technicians for common failure modes. The unpredictability of when they occur is the challenge, not the discovery itself.
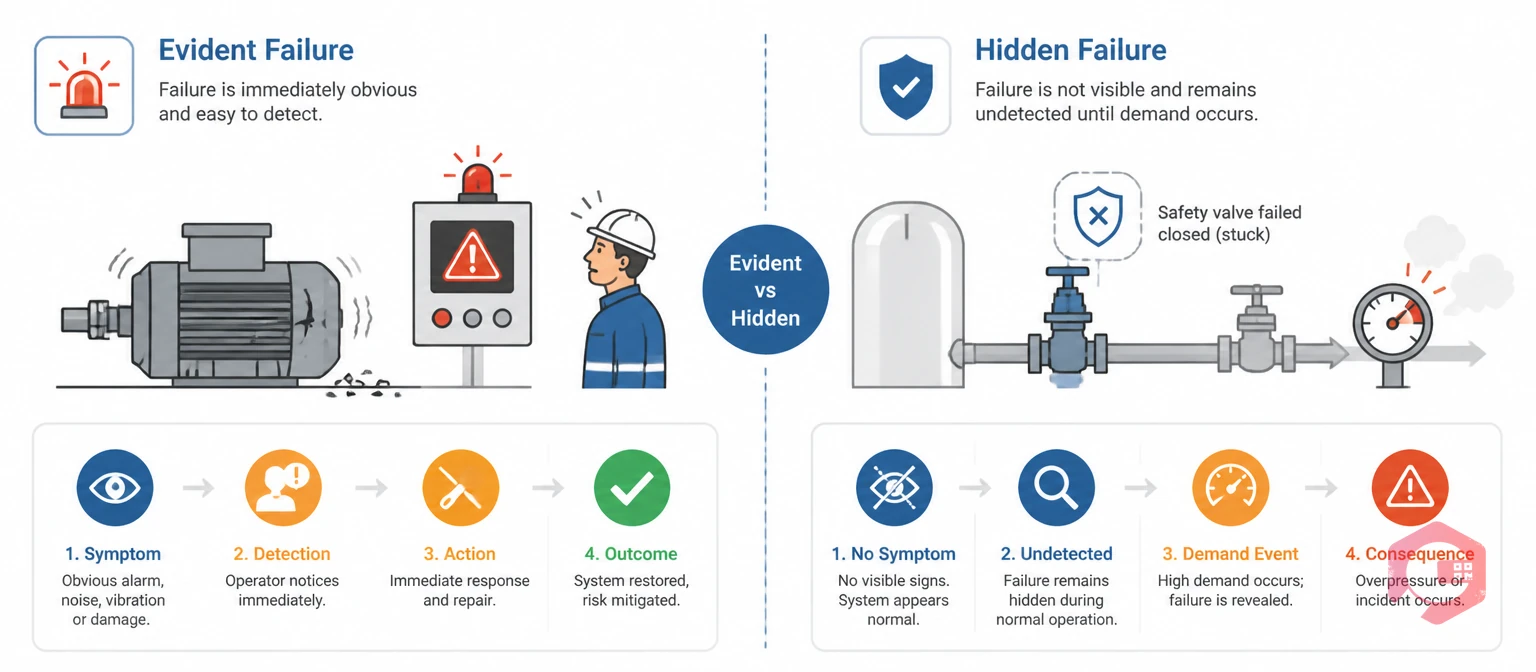
A hidden failure is a failure that has already occurred but is not apparent during normal operation. The asset or component has lost its intended function — but nobody knows it yet. These failures are particularly dangerous in protective systems: backup generators, safety relief valves, fire suppression systems, and redundant control circuits. They only reveal themselves when they are demanded to function in an emergency — and fail to do so.
The term comes directly from Reliability-Centered Maintenance methodology, where hidden failure is a distinct classification requiring its own maintenance strategy. According to the original RCM framework developed for the aviation industry in the 1970s and later adopted across manufacturing and oil and gas, hidden failures cannot be managed through run-to-fail strategies or standard reactive maintenance — they require dedicated scheduled tasks or condition monitoring to uncover them before they create a multiple failure scenario.
Understanding exactly how these two failure types differ helps maintenance teams assign the right strategy to each asset function. Here's a direct comparison across the attributes that matter most for maintenance planning:
| Attribute | Evident Failure | Hidden Failure |
|---|---|---|
| Operator awareness | Immediately noticed | Not noticed during normal operation |
| Detection method | Visual, audible, or alarm-based | Requires scheduled testing or condition monitoring |
| Common asset types | Primary operating equipment | Protective and standby systems |
| Risk if unmanaged | Downtime, production loss | Multiple failure, safety incident |
| Maintenance strategy | Reactive or time-based PM | Failure-finding tasks or CBM |
| RCM classification | Evident function | Hidden function |
| Impact on MTBF | Directly measurable | Often unknown without systematic tracking |

The core danger of a hidden failure is not the failure itself — it's what happens when a second failure occurs in a system where the protective layer has already silently failed. This is called a multiple failure, and it is the scenario behind many of the worst industrial accidents on record.
Consider a fire suppression system in a chemical plant. If the suppression system has a hidden failure (a blocked nozzle, a dead sensor), the plant continues to run normally. Nobody notices. Then a fire breaks out — an evident failure. At that moment, the suppression system is demanded to perform and it can't. The result is not just an equipment failure; it's a safety catastrophe.
From a financial standpoint, hidden failures are the most expensive category of maintenance event when they finally surface. A McKinsey analysis of industrial maintenance costs found that unplanned failures driven by undetected degradation cost 5 to 10 times more to fix than failures caught through scheduled maintenance. The cost gap comes from emergency labour rates, expedited spare parts, collateral damage to connected equipment, and — in safety-critical scenarios — regulatory fines and liability.
Beyond financial cost, there's the MTBF problem. Because hidden failures don't register as failure events until they surface, your MTBF calculations are systematically overestimating the reliability of protective assets. You think the backup generator is reliable because it's never failed — but it's never been properly tested.
Hidden failures are found across every industry and equipment class, but they're most concentrated in assets that only operate under specific conditions. Here are the most common examples maintenance teams encounter:
According to the UK Health and Safety Executive's guidance on safety-critical systems, the majority of safety system failures at industrial sites are hidden failures that had no visible sign prior to the demand event.
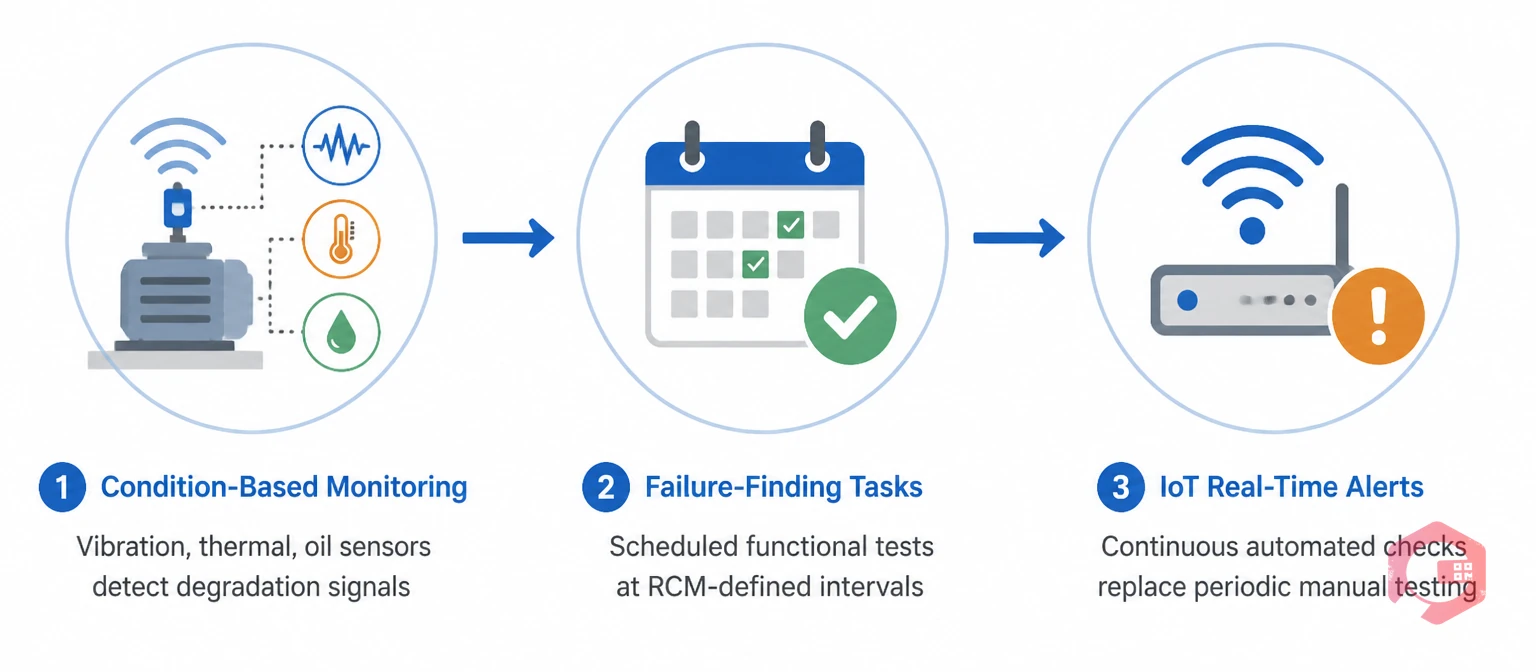
Because hidden failures don't announce themselves, you need a systematic approach to surface them. There are three proven methods, and the best maintenance programs use all three in combination.
Condition-based maintenance (CBM) uses real-time data from sensors, vibration analysis, thermal imaging, and oil sampling to detect degradation before it becomes a failure. For hidden failures specifically, CBM is effective when the failure mode produces a measurable signal — even if that signal isn't visible to operators. A bearing that's about to fail in a standby pump will show elevated vibration long before it seizes. A heat exchanger with scale buildup will show rising outlet temperatures. The signal is there; you just need the monitoring tools to catch it.
For assets where no condition monitoring signal is practical, scheduled preventive maintenance with defined failure-finding tasks is the standard approach. A failure-finding task is specifically designed to reveal hidden failures: you test the safety relief valve, load-test the backup generator, functionally test the fire suppression zone. The interval is set based on the acceptable probability of the hidden failure existing and not being discovered — a concept directly from RCM analysis.
Modern IoT-connected maintenance systems can automate much of the hidden failure detection process. Sensors on standby and protective assets continuously transmit status data. When readings drift outside defined thresholds — pressure, temperature, voltage, cycle count — an alert is generated automatically. This turns what was formerly a periodic manual test into a continuous automated check, drastically reducing the window in which a hidden failure can remain undetected.
Reliability-Centered Maintenance and Failure Modes and Effects Analysis (FMEA) are the two most effective frameworks for systematically identifying and managing hidden failure risks across an asset portfolio.
In an RCM analysis, every asset function is classified as either evident or hidden. Hidden functions get a specific maintenance task type called a "failure-finding task" — an interval-based inspection or test designed specifically to reveal the hidden failure before it creates a multiple failure scenario. The interval calculation is rigorous: it accounts for the probability of the hidden failure occurring, the acceptable risk level, and the consequence of the multiple failure.
FMEA adds the layer of consequence analysis. For each identified hidden failure mode, FMEA assesses the severity of the multiple failure, the likelihood of detection under current maintenance practices, and the overall risk priority number (RPN). High-RPN hidden failure modes are the first candidates for new monitoring investments or revised maintenance intervals. ISO 55001 asset management standards specifically require organizations to have documented processes for identifying and managing hidden failure risks in safety-critical systems.
A computerized maintenance management system (CMMS) is the operational backbone for any hidden failure management program. Without it, failure-finding tasks get missed, interval compliance is impossible to track, and the data needed to calculate your true hidden failure rate doesn't exist.
With Cryotos CMMS, maintenance teams can set up automated preventive maintenance schedules with dedicated failure-finding task types, assign them to specific assets in their protective function categories, and track completion rates in real time. The IoT integration feeds live sensor data directly into the platform — so when a standby pump's vibration reading crosses a defined threshold, a work order is generated automatically before anyone even picks up a phone. The BI dashboard then gives you an asset-level view of hidden failure risk, sorted by RPN or last-tested date, so your maintenance team always knows where the exposure is highest.
Teams using Cryotos have reported 30% reductions in unplanned downtime — a number that reflects exactly this kind of systematic hidden failure management, where the most dangerous events get caught before they cascade into multiple failures.
A hidden failure is a failure that has already occurred but is not noticeable during normal operations. The asset has lost its function, but the loss isn't apparent until the asset is tested or called upon to perform — typically during an emergency or a scheduled inspection.
An evident failure is immediately obvious when it occurs — operators notice it through alarms, noise, or loss of output. A hidden failure has no observable symptoms during normal operation and can only be discovered through deliberate testing, inspection, or condition monitoring.
Hidden failures are dangerous because they silently disable protective functions. When a primary failure then occurs in the same system, the protective device that should intervene has already failed. This combination — called a multiple failure — is behind most major industrial accidents and is typically far more costly and damaging than any single evident failure.
The three main methods are: scheduled failure-finding tasks (functional testing at defined intervals), condition-based monitoring using sensors and vibration analysis, and IoT-enabled real-time alerts that flag when asset readings drift outside safe parameters. A CMMS is essential for tracking all three methods systematically across a large asset portfolio.
Protective and standby assets are the highest-risk category: backup generators, safety relief valves, standby pumps, fire suppression systems, gas and smoke detectors, and redundant control systems. These assets operate infrequently or only under abnormal conditions, which means their failure can go undetected for extended periods.
Hidden failures don't stay hidden forever — they surface at the worst possible moment, when you least expect them and most need the protection they were meant to provide. The good news is that with the right maintenance strategy, systematic testing intervals, and a modern CMMS to track it all, you can close the gap between failure and discovery to near zero. See how Cryotos CMMS helps maintenance teams detect hidden failures before they become disasters — with IoT integration, automated PM schedules, and real-time asset health monitoring built in from day one.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











