
Incident management in maintenance is the structured process of detecting, logging, responding to, and resolving unexpected equipment failures to restore normal operations quickly. Unlike scheduled preventive work, a maintenance incident is unplanned. It demands an immediate response from the right people with the right tools.
Done well, incident management reduces unplanned downtime and protects asset life. It builds the data trail that stops the same failure from happening again.
OSHA recordkeeping rules require that any incident that disrupts safe operation must be logged with root cause and corrective action. Teams that do this recover faster. They spend less on emergency repairs. And they catch chronic failure patterns months before those patterns become crises.
Key Takeaways

A maintenance incident is any unplanned event that stops an asset, system, or process from working normally. It differs from a planned maintenance task in one key way: it was not scheduled, and it demands an immediate response.
Incidents range from a conveyor belt slipping off its track to a motor failure that halts an entire production line. What ties them together is urgency. The team needs a response now, not next week during the scheduled window.
The ISO 55000 asset management standard defines incidents as events that fall outside the expected asset performance range. This shifts the focus from blame to data. An incident is a signal from the asset — not a failure of the maintenance team.
Most maintenance incidents share three key traits. These traits help teams tell an incident from a routine task.
Not all maintenance incidents are equal. Knowing the category helps teams respond faster, use the right resources, and pick the correct fix. The five most common categories cover the vast majority of what maintenance teams face.
This is the most common type. A component stops working — a pump seal fails, a bearing seizes, or a drive belt snaps. The team must respond fast. Corrective maintenance is the immediate fix, but a proper incident record must capture why the failure occurred, not just that it did.
The asset is still running but no longer performs within specification. A compressor produces lower-than-rated pressure. A conveyor runs 15% below rated speed. These incidents are often harder to detect because production continues. But they signal impending failure if left unaddressed.
Any event that creates a hazard to people, product, or the environment. A machine guard becomes dislodged. A pressure relief valve fails. A refrigeration unit exceeds safe temperature limits in a food area. These incidents require immediate isolation and may trigger regulatory reporting obligations.
Failures in supporting systems — electrical supply interruptions, compressed air pressure drops, cooling water flow failures — that cascade into production equipment problems. These are often overlooked in asset-level incident tracking but cause significant secondary downtime.
Events triggered by upstream condition changes rather than mechanical failure. Raw material variability may cause equipment to run outside design parameters. Operator error may load an asset beyond its rated capacity. These require a different response path because the root cause lies outside the maintenance team's direct control.
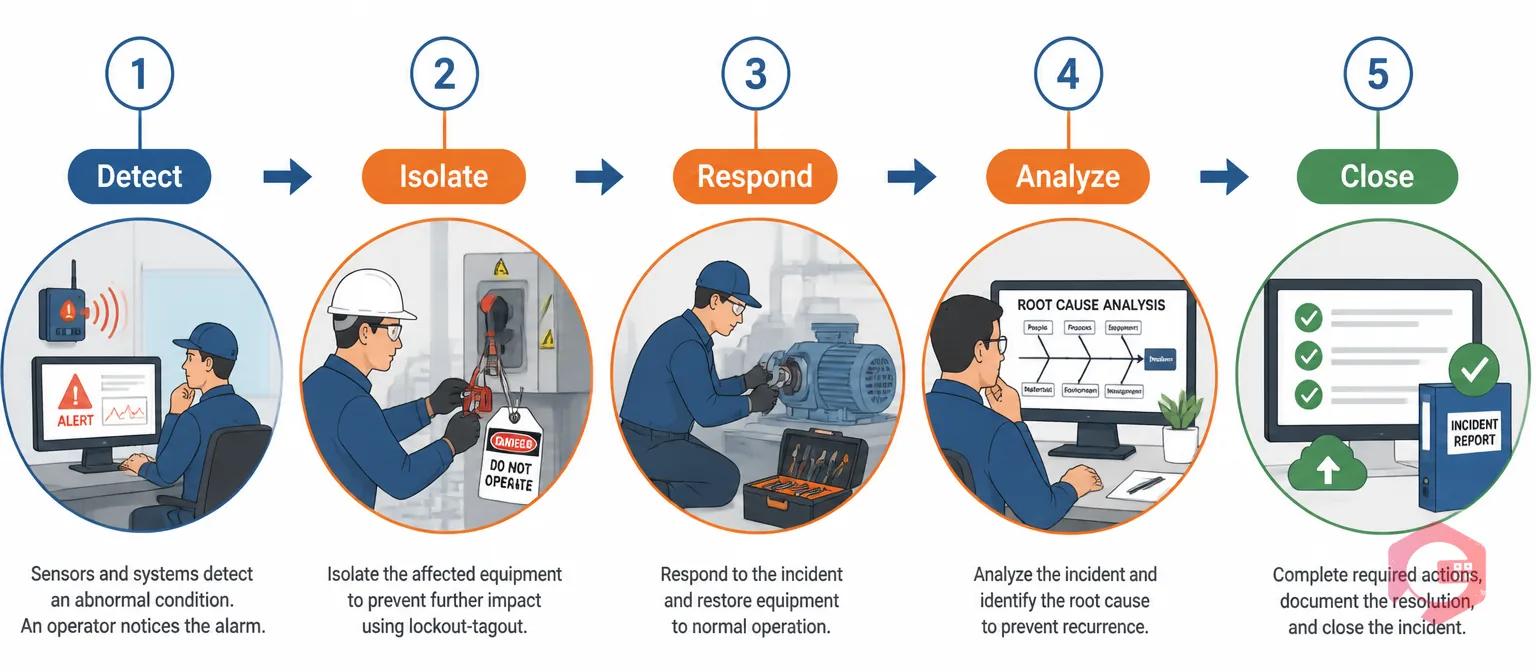
A structured incident management process turns a chaotic emergency into a repeatable, data-driven workflow. Teams without a defined process spend more time per incident. They are also more likely to see the same failure repeat. A clear process changes both of those outcomes. It gives everyone the same steps to follow — every time an incident occurs.
The DIRAC Incident Management Framework gives maintenance operations a clear, five-stage structure that works across industries, asset types, and team sizes:
Track how quickly your team moves through the Respond and Close stages with the free MTTR Calculator. It is a direct measure of your incident management speed. Use it to set a baseline and track progress over time.

Effective incident management converts unplanned failures from pure cost into actionable intelligence. Teams that treat each incident as a data event — not just a repair task — build the knowledge base that separates high-performing operations from reactive ones.
Unplanned downtime can cost $50,000 to $250,000 per hour in industrial environments. Emergency repair labor runs 1.5 to 3 times higher than planned rates. Rush parts orders add premium costs that planned purchasing avoids entirely.
Maintenance teams using Cryotos have reported up to 30% less unplanned downtime and 25% faster repairs. They achieve this by using structured incident workflows and reviewing the resulting downtime tracking data.
Most facilities track PM compliance as their main maintenance KPI. Incident data is the missing piece. It shows how the system held up when the plan was disrupted — not just how well planned work was done.
Most chronic problems are visible in well-kept incident records months before they become critical. The patterns are there. But only teams that log incidents the same way every time can see them. Inconsistent records hide patterns. Structured records reveal them.
Many maintenance teams use "incident management" and "corrective maintenance" as the same term. They are related but not identical. Understanding the difference matters. It prevents important steps from being skipped when the pressure is high.
| Aspect | Incident Management | Corrective Maintenance |
|---|---|---|
| Scope | End-to-end process: detect, isolate, respond, analyze, close | The repair task only — restoring the asset to working condition |
| Trigger | Any unplanned operational disruption | A confirmed equipment failure requiring physical repair |
| Ownership | Shared: operations, maintenance, safety, management | Primarily the maintenance technician and supervisor |
| Data captured | Detection time, isolation steps, response time, RCA, closure documentation | Fault found, action taken, parts used, time to repair |
| Outcome goal | Restore operation AND prevent recurrence | Restore operation |
| KPI produced | MTTR, incident frequency, time-to-detect, recurrence rate | Repair time, parts cost, labor hours |
Corrective maintenance happens inside every incident. But not every repair is part of a formal incident management process. When a technician replaces a worn belt during a scheduled PM, that is corrective maintenance — planned and routine. When a production line stops because a belt snapped without warning, and the team detects it, isolates the machine, fixes it, and finds out why the belt failed early — that is incident management. One is a task. The other is a system.
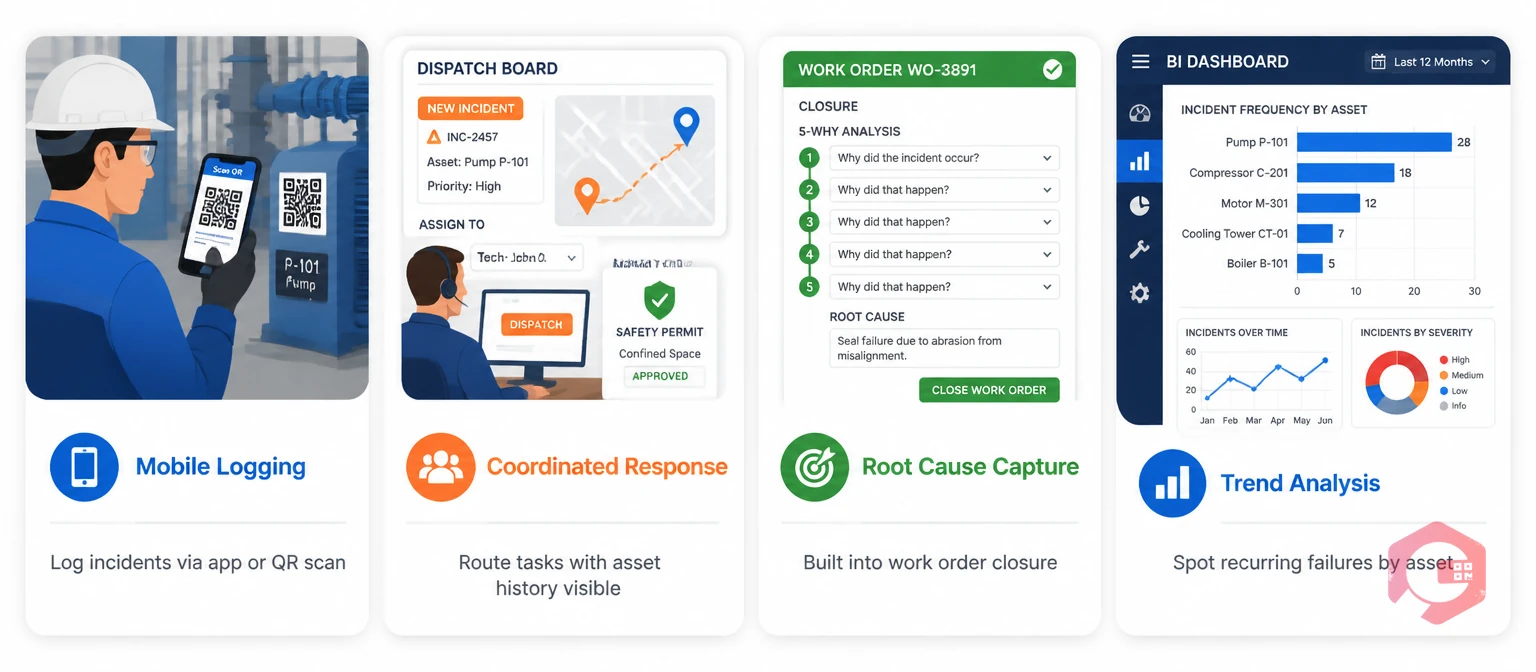
A Computerized Maintenance Management System transforms incident management from a manual process into a structured, data-driven workflow that speeds up response and prevents recurrence. Without a CMMS, incidents are logged in different ways by different people. Root cause analysis gets skipped under pressure. The data never builds into something useful.
Cryotos maintenance management software supports every stage of the DIRAC framework. It gives teams one place to log, respond, analyze, and close every incident. Here is how each stage works in practice.
Incidents can be logged from the plant floor via mobile app, QR scan, or WhatsApp. IoT sensor links let Cryotos detect threshold breaches on its own — a motor temperature spike, a pressure drop — and open a work order before anyone reports the problem.
Once an incident is logged, the task is routed to the right technician. Asset history, past repairs, and required parts are all visible at once. Safety steps — Permit to Work and Lockout/Tagout — are built into the work order, so isolation steps are always documented.
Cryotos builds the 5 Whys root cause analysis into the work order closure flow. A technician cannot close an incident work order without logging the root cause. This means the analysis happens while the failure is fresh. Over time, this builds an asset-level failure history that any team member can search.
The BI Dashboard shows incident frequency by asset, department, and failure mode. When the same failure appears on the same asset three times in six months, the dashboard flags it. Planners can then build a targeted PM schedule — moving that asset from reactive response to proactive protection.
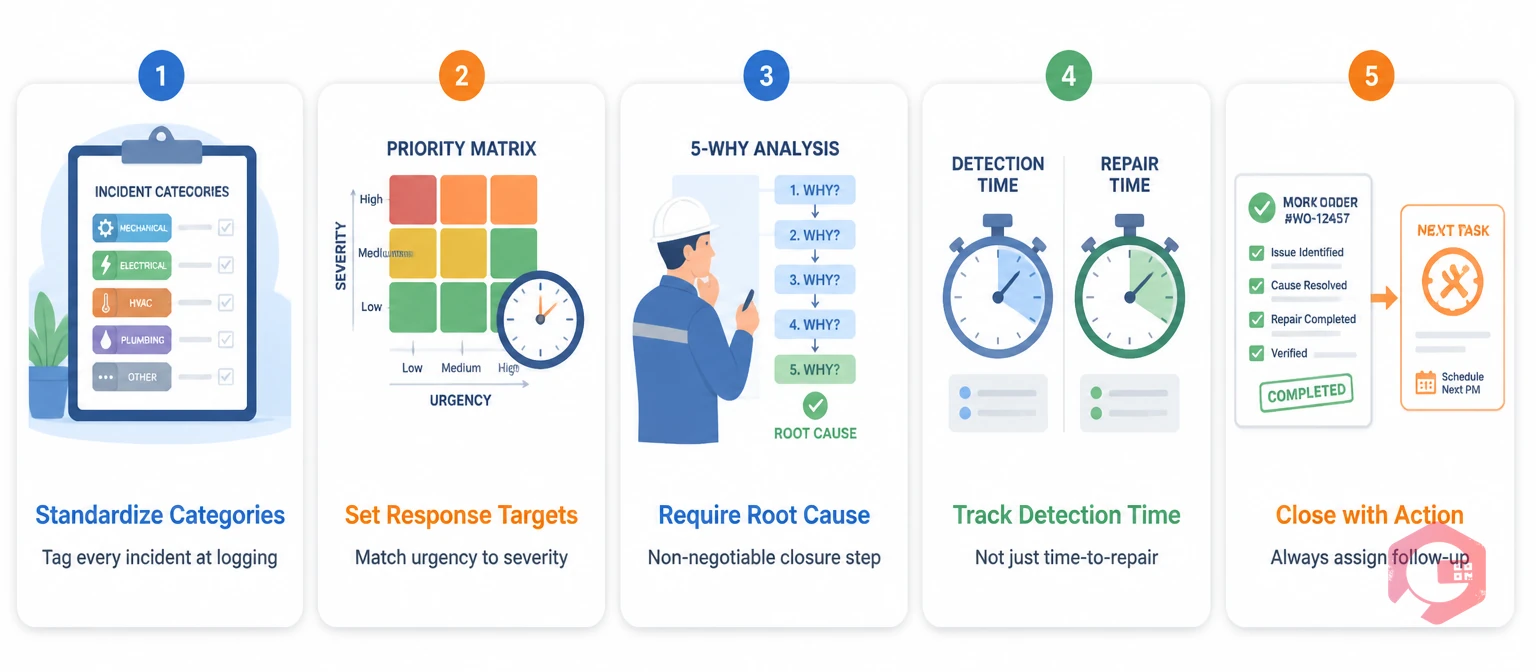
Most maintenance operations already respond to incidents. The teams that outperform do it differently in five consistent ways.
Tag every incident with a standard category when you log it. Use labels like: equipment failure, performance issue, safety event, utility failure, or process-related. Without categories, your data is hard to sort. With them, you can quickly see which types take the most response time or happen most often. This is the first step to a data-driven maintenance program. It takes 30 seconds per incident. Over time, the return is significant.
Not all incidents need the same urgency. Most teams use a priority matrix with set response time targets. A safety-critical incident needs an immediate response. A minor performance issue on a low-risk asset can wait up to 24 hours. Clear targets give dispatchers a framework. They also give management a KPI to track.
The biggest predictor of a repeated incident is an incomplete root cause record from last time. Teams that skip RCA under pressure pay for it with recurring failures. The 5 Whys method takes 10 to 15 minutes when built into the closure workflow. That is far cheaper than the next occurrence of the same incident.
Most teams track MTTR — the time from incident open to close. Fewer track time-to-detect — the lag between when the failure happened and when it was logged. Reducing that lag requires better detection tools: operator rounds, sensors, and a culture where anyone can log an incident in 30 seconds. That gap is where production losses pile up before maintenance even knows there is a problem.
A well-closed incident always says what happens next: a PM change, a parts reorder, a checklist update, or an inspection of similar assets. If the record says "repaired — no further action," the team missed the learning the incident offered. Consistent workflow automation at closure is how programs improve over time.
Preventive maintenance is scheduled work done to reduce the chance of failure — oil changes, filter swaps, calibration checks. Incident management is the response process when something fails without warning, despite those efforts. Both are part of a full maintenance program. Preventive maintenance cuts how often incidents happen. Incident management makes sure that when they do happen, they are resolved fast and documented well enough to prevent recurrence.
The main metric is Mean Time to Repair (MTTR). This measures the time from incident detection to normal operation. Other key KPIs are time-to-detect, incident recurrence rate, and root cause completion rate. A healthy process shows MTTR going down over time. It also shows low recurrence rates and near-100% root cause capture on all closed records.
A complete incident record needs several key items. These are: the asset name and ID, the time the incident was detected, the symptom or failure mode, the isolation steps taken, the technician assigned, the root cause found, the corrective action taken, parts and labor used, and a follow-up action to prevent recurrence. Records that skip any of these limit the team's ability to find patterns and improve.
Yes. The key requirement is consistency, not a big system. Even a two-person team benefits from logging every incident with the same fields: asset, time, symptom, cause, action, follow-up. A CMMS with mobile logging makes this easy. Setup takes a day. Within 90 days, most small teams find two or three chronic failure patterns they did not know about. Then they can take direct action to stop them from recurring.
A CMMS replaces phone calls, paper job cards, and memory with a single searchable record. It captures detection, response, repair, and root cause in one place. When the same asset fails again six months later, the technician sees every prior incident — the root cause, the parts used, and the repair time. That context cuts diagnosis time and stops past mistakes from repeating.
Incident management is one of the highest-leverage processes in any maintenance program. Not because incidents are inevitable — but because how you handle them decides whether they stay isolated events or become costly recurring patterns. Teams that manage incidents well spend less on repairs. They recover faster. And they build more reliable assets over time. Schedule a free demo to see how Cryotos structures incident logging, root cause capture, and trend analysis to turn every maintenance incident into a step toward a more reliable operation.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











