
The 7 questions of Reliability Centered Maintenance (RCM) are a structured analytical framework that determines the right maintenance task for every asset in your plant. Developed in the aviation industry and later standardized in SAE JA1011, the process walks you through seven questions in a fixed sequence — from defining what an asset does, through identifying failure modes and consequences, to selecting a proactive maintenance task or redesign. Every question builds on the one before it, and skipping any one of them leads to the wrong task assignment.
This guide explains each of the 7 RCM questions in plain language, shows how they apply to a real industrial asset, and maps the outputs directly to the maintenance tasks and CMMS records that put the analysis to work. Whether you're starting your first RCM program or auditing an existing one, this is the sequence you'll rely on.
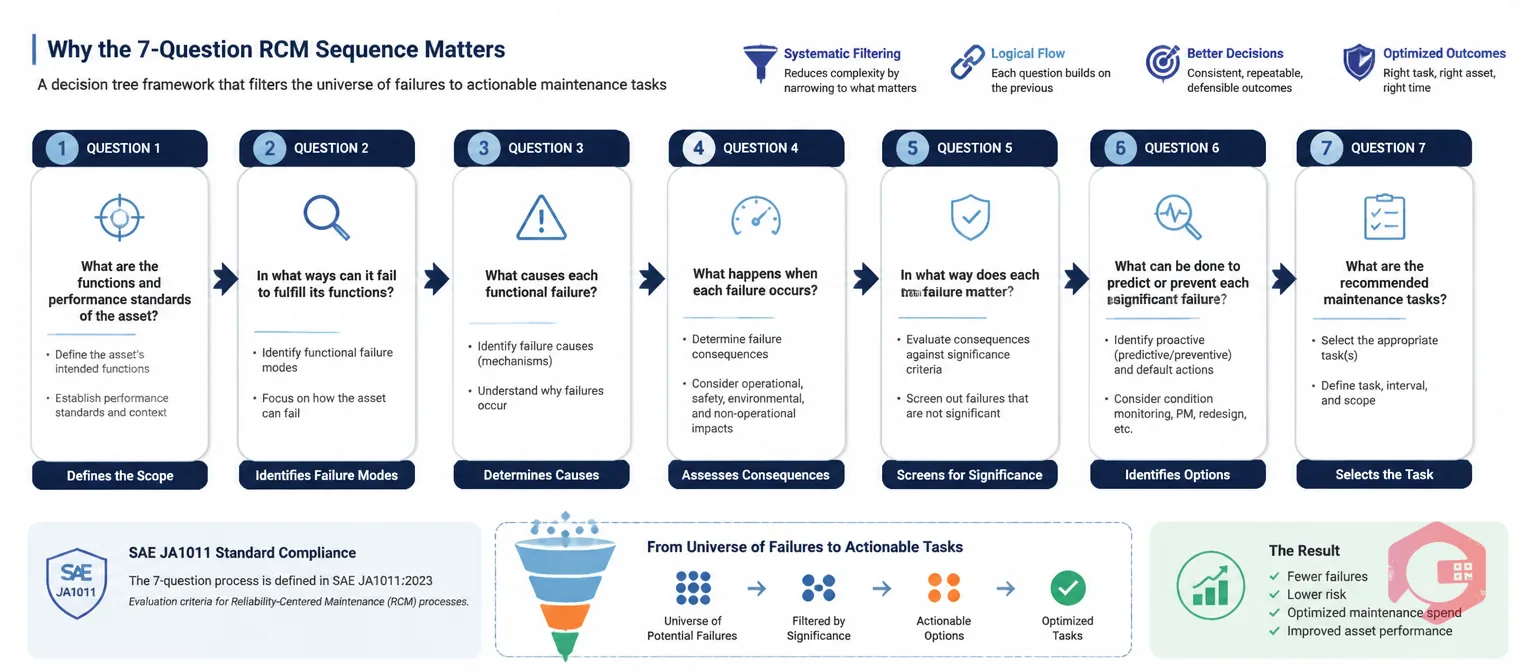
RCM isn't just a list of questions — it's a decision tree. Each question is designed to filter the universe of possible failures down to the ones that actually matter in your operating context, and then to assign a maintenance response that is technically sound and worth doing economically. The sequence matters because you can't answer Question 3 (what causes the failure?) without first answering Question 2 (what constitutes a failure?), and you can't select the right task in Question 6 without first understanding the consequences in Question 5.
According to SAE JA1011, the international standard for RCM processes, a process only qualifies as RCM if it satisfies all seven questions for every significant failure mode of every asset in its operating context. Plants that shortcut the sequence tend to reproduce the same over-maintained, under-justified schedules they were trying to fix. Done correctly, RCM analysis routinely eliminates 30–40% of time-based tasks that have no failure-mode justification while identifying condition-monitoring needs that were previously missed.
You can use the MTBF calculator to baseline your current equipment reliability before starting the analysis — the gaps between where you are and where you want to be will sharpen the priority order for which assets to analyze first.
The first question defines the function of the asset in its current operating context. This is not the same as what the asset was designed to do — it's what your plant actually needs it to do, at what performance level, right now. An asset can have multiple functions: a primary function (the main reason it exists) and several secondary functions (protecting the environment, containing pressure, providing operator safety, meeting regulatory requirements).
For example, a centrifugal pump in a cooling water circuit has a primary function of delivering 200 m³/hr of cooling water at a pressure sufficient to maintain reactor temperature below 80°C. Secondary functions might include containing process fluid without leaking and operating without generating noise above a site threshold. Both matter — failing either one has consequences you need to track.
This question forces the team to be specific. Vague function statements like "pump water" produce vague failure definitions and, eventually, vague maintenance tasks. The more precise the function statement, the more precisely you can define when the asset has failed to deliver it — which is exactly what Question 2 requires.
Question 2 asks for a list of functional failures — the specific ways the asset can fail to deliver each of its required functions. A functional failure is not a component failure (a bearing overheating) but a function failure (the pump fails to deliver 200 m³/hr). The distinction is important because multiple different component failures can produce the same functional failure, and a good RCM analysis tracks both levels.
For the cooling pump, functional failures might include: fails to deliver any flow (total loss of function), delivers flow below the required rate (partial loss of function), or delivers flow but at inadequate pressure (degraded performance). Each functional failure becomes its own branch of the analysis tree, because the causes and consequences of each can be very different.
Most assets have 2–5 functional failures when you think through all their functions carefully. This list drives the entire downstream analysis — so teams that rush Question 2 end up with an incomplete Failure Modes and Effects Analysis (FMEA) and miss failure modes that are actually occurring on the plant floor.
Question 3 identifies the failure modes — the specific physical causes behind each functional failure. For each functional failure defined in Question 2, the team asks: what can cause this function to stop being delivered? The answer is typically a list of hardware, process, or human-factor causes, each of which becomes a separate failure mode to be analyzed.
For "pump delivers no flow," failure modes might include impeller erosion, seal failure causing loss of prime, motor burnout, or a blocked suction strainer. For "pump delivers insufficient pressure," the causes are different — impeller wear, incorrect rotation direction after rewiring, or operating outside the design curve due to system changes. Each cause produces a different maintenance response, which is why the analysis must reach this level of specificity.
A useful benchmark: a complex rotating machine like a pump typically yields 20–40 failure modes across all its functional failures. Simpler assets may have 5–10. Document each one in your CMMS asset record — Cryotos CMMS supports this through its AI-powered knowledge base, where failure history and technical notes can be stored against specific assets and retrieved during future analyses or work order creation.
Question 4 asks for a description of the failure effects — what actually happens when this failure mode occurs? This is not the same as the consequences (that comes in Question 5). Effects are observable, physical descriptions: what does the operator see, hear, or smell? What alarms are triggered? Does production stop immediately or degrade gradually? How long does restoration typically take?
For impeller erosion in the cooling pump, the effects might be: gradual reduction in flow rate over weeks, increased power draw, elevated reactor temperatures appearing on the control system, and eventual high-temperature alarm. For seal failure, the effect is immediate — loss of prime, pump cavitation, no flow, and a potential fluid release at the seal face.
Recording failure effects in detail serves two purposes. First, it enables operators to recognize the failure early, which is critical for failure detection tasks assigned in Question 6. Second, it populates the evidence base for Question 4's downstream partner — the consequences assessment in Question 5. Good effects documentation is what separates an RCM analysis that produces actionable tasks from one that produces generic checklists. Your work order management system should capture failure effects as part of every corrective work order so that patterns become visible over time.
Question 5 categorizes the consequences of each failure mode. RCM uses a specific consequence classification that drives the task selection logic in Questions 6 and 7. The four consequence categories are: safety consequences (potential to injure or kill people), environmental consequences (potential to breach a regulatory limit or cause environmental damage), operational consequences (impact on output, quality, or cost that the plant owner bears), and non-operational consequences (no effect on safety, environment, or output — only the direct cost of repair).
This question is the most critical gate in the entire process. A failure mode with safety or environmental consequences must have a proactive maintenance task that reduces the probability of the failure to an acceptable level — or the asset must be redesigned. Failure modes with only operational consequences need tasks that are economically justified: the cost of the task must be less than the cost of the failure. Failure modes with non-operational consequences only need to be fixed when they occur — a run-to-failure strategy is the right answer.
This is why RCM frequently produces schedules that look very different from traditional time-based PM programs. A plant that runs everything on time-based intervals is implicitly treating all failure modes as though they have the same consequence category — which is almost never true. Categorizing properly in Question 5 lets you focus your maintenance budget and technician time where failures actually matter. The downtime tracking module in Cryotos CMMS provides the operational cost data you need to make this consequence assessment with real numbers rather than estimates.
Question 6 is where the maintenance task is selected. For each failure mode with significant consequences (safety, environmental, or high-cost operational), the team asks: is there a proactive task that is technically feasible and worth doing? RCM recognizes three types of proactive tasks, each with a specific technical applicability test.
A scheduled restoration task (restoring or replacing a component on a fixed interval) is applicable only if the failure mode has an identifiable age-related wear pattern — the component's probability of failure increases with age. A scheduled discard task (replacing a component before it reaches a defined age limit) applies similarly. An on-condition task (monitoring a condition indicator that warns of impending failure) is applicable when the failure has a detectable potential-failure condition before it becomes a functional failure — the P-F interval must be long enough for the monitoring frequency to catch it in time.
For our pump's impeller erosion: impeller wear is age-related and detectable by monitoring flow performance and bearing vibration — so an on-condition task (monthly vibration analysis plus quarterly flow test) is technically applicable. For seal failure: seal life is not strongly age-related in most service conditions, so a time-based replacement is not justified. Instead, a monthly oil sample to detect water ingress and a daily visual check for leakage are the appropriate on-condition tasks. Pairing IoT meter reading with your RCM-derived condition monitoring tasks automates the data collection side of these on-condition checks.
Question 7 deals with failure modes where no technically feasible proactive task exists — or where the failure has no significant consequences and running to failure is the right answer. RCM provides two default actions for these situations: a failure-finding task or a one-time redesign recommendation.
A failure-finding task applies to hidden failures — failures that don't make themselves known during normal operation until a second failure occurs (for example, a standby pump that hasn't been tested and is actually failed, but no one knows because it isn't running). Failure-finding tasks are periodic functional tests designed to detect hidden failures before the operational demand reveals them. The task interval is set based on the tolerable probability of the hidden failure being present at the moment demand occurs.
A redesign recommendation applies when a failure mode has serious safety or environmental consequences but no proactive task can reduce the risk to an acceptable level. In this case, the equipment design, operating procedure, or protection system must change. This is a significant finding — one that a traditional PM program would never surface — and it's one of the most valuable outputs of a thorough RCM analysis.
For failure modes with non-operational consequences and no applicable proactive task, the correct default is run to failure with a corrective maintenance plan ready. This isn't neglect — it's an informed decision that allocating maintenance resources here would cost more than the failure itself. Documenting this decision in your work order system as a standing corrective task ensures the response is fast when the failure does occur.
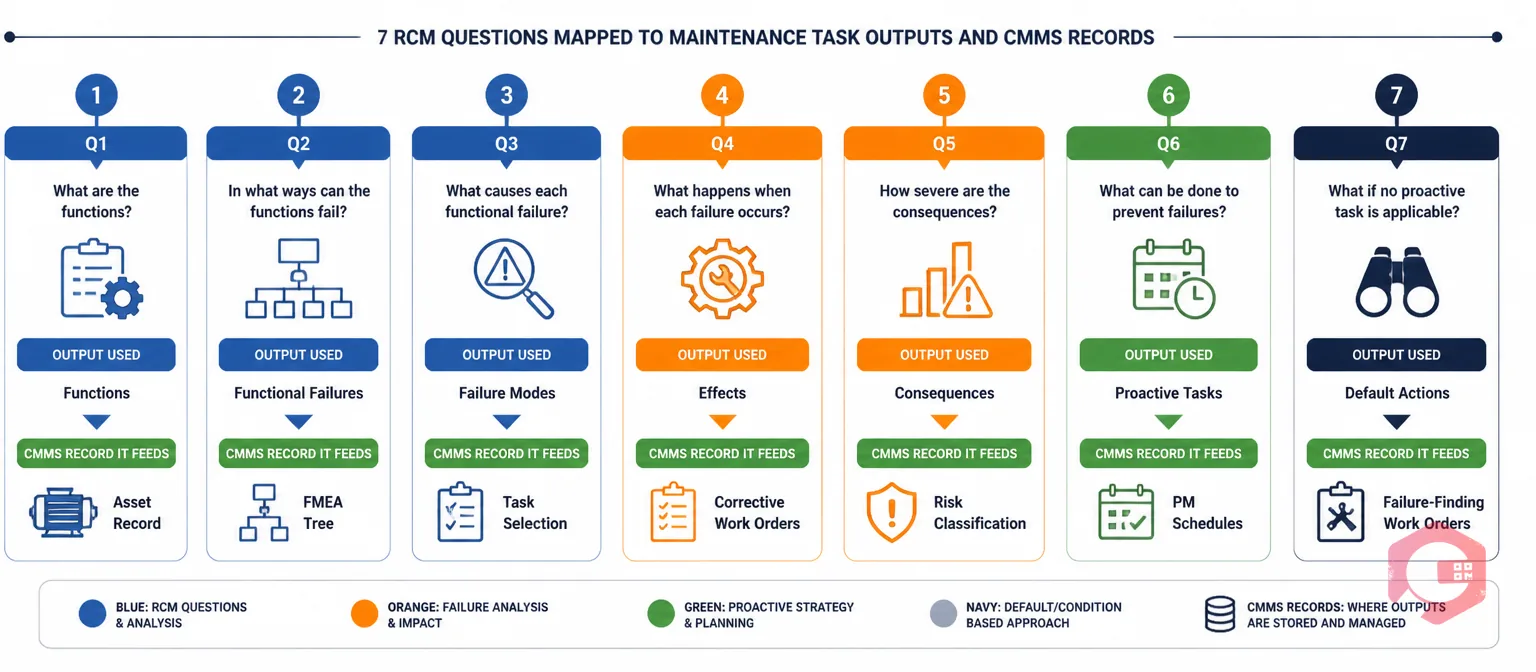
| Question | What It Establishes | Output Used In | CMMS Record It Feeds |
|---|---|---|---|
| Q1: Functions | What the asset must do and at what level | Defines the scope of all downstream questions | Asset record — function statements |
| Q2: Functional failures | Ways the asset can fail to deliver its function | Branches the FMEA analysis tree | Failure category list in asset record |
| Q3: Failure modes | Physical causes of each functional failure | Drives task selection in Q6/Q7 | Failure mode library; FMEA worksheet |
| Q4: Failure effects | Observable evidence when failure occurs | Enables operator detection; informs Q5 | Corrective WO failure description field |
| Q5: Consequences | Why this failure matters (safety/env/operational) | Sets task justification threshold for Q6 | Risk classification on asset/failure mode |
| Q6: Proactive tasks | On-condition, restoration, or discard tasks | PM schedule tasks and intervals | Preventive maintenance work orders |
| Q7: Default actions | Failure-finding tasks or redesign recommendations | Functional test schedules; engineering change requests | Failure-finding WOs; standing corrective tasks |
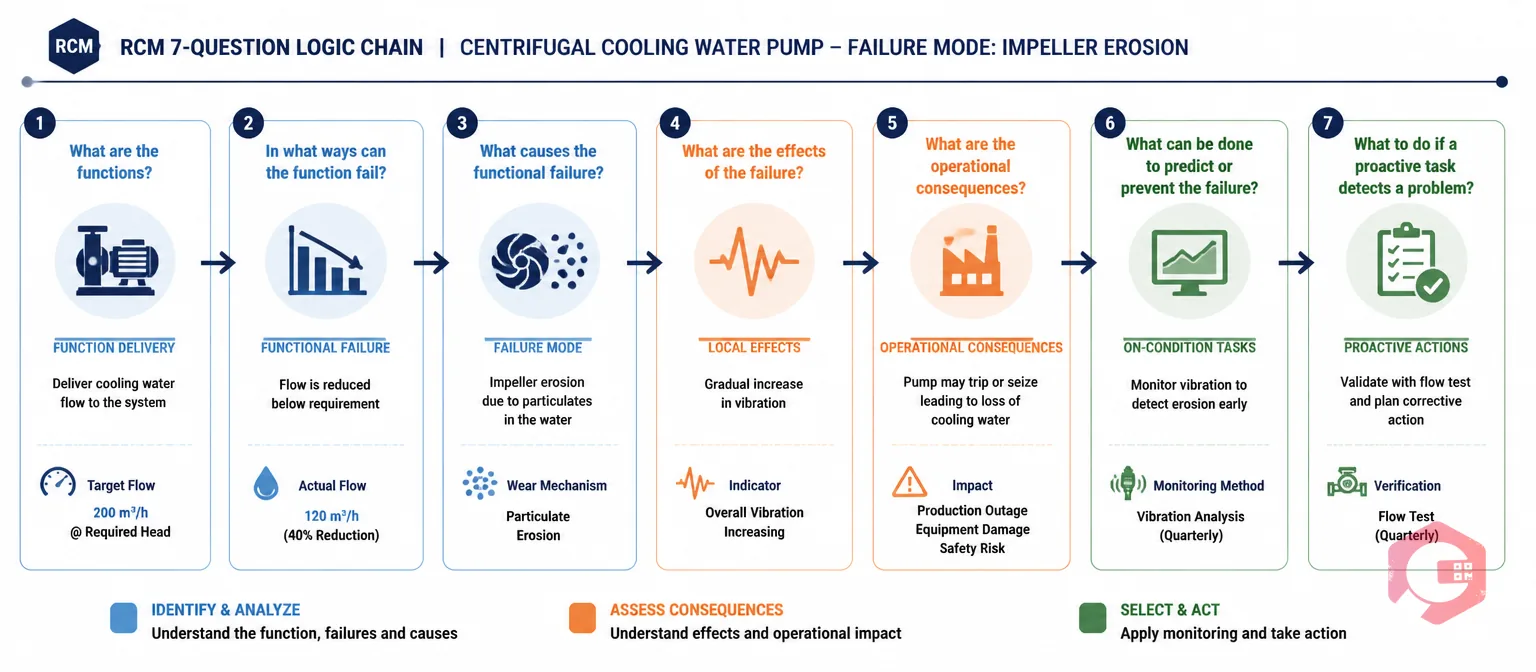
Here's how the seven questions apply to a single failure mode — impeller erosion in a cooling water pump — in a compact, practical format that shows the chain of logic from function to task.
Q1 (Function): Deliver 200 m³/hr cooling water to maintain reactor temperature below 80°C during normal operation. Q2 (Functional failure): Delivers less than the required flow rate. Q3 (Failure mode): Impeller wear due to particulate erosion in untreated cooling water. Q4 (Failure effects): Gradual flow reduction over 6–12 months; elevated bearing vibration; high-temperature alarm activation before functional failure. Q5 (Consequences): Operational — process temperature exceedance causes batch rejection and 4-hour production outage estimated at $40,000. Q6 (Proactive task): On-condition — monthly vibration analysis on pump bearings; quarterly flow performance test against design curve. Replace impeller when vibration exceeds 7 mm/s or flow drops below 185 m³/hr. Q7 (Default action): Not applicable — a proactive on-condition task was found in Q6.
This logic chain takes roughly 15 minutes per failure mode with a trained facilitator and a cross-functional team. Documenting it in a maintenance checklist linked to the asset in your CMMS ensures the task rationale stays attached to the schedule, not buried in an offline spreadsheet. When engineers turn over or equipment changes, the reasoning behind the task is still visible — which is what makes RCM programs durable.
Plants that implement the 7-question RCM process through manufacturing maintenance software typically see maintenance costs fall by 25–35% and equipment availability improve by 10–20% within the first two years, according to SMRP benchmarking data. The 7 questions are the analytical engine — the CMMS is what converts the analysis into scheduled action, tracked compliance, and measured results.
A typical RCM analysis for a moderately complex asset (20–40 failure modes) takes 4–8 hours of facilitated team time when spread across 2–3 sessions. Simpler assets with fewer failure modes can be completed in 2–3 hours. The biggest time investment is usually in getting the right people in the room — operators, maintainers, and engineers who collectively know how the asset actually behaves in service.
Dedicated RCM software (such as Isograph Availability Workbench or Clockwork RCM) helps manage large programs with hundreds of assets, but it's not required to start. Many plants run their first RCM analyses in structured spreadsheets and then migrate the task outputs into their CMMS. What matters most is that the CMMS can receive and schedule those tasks, link them to the correct asset, and track compliance over time.
FMEA (Failure Modes and Effects Analysis) is the analytical tool embedded in Questions 2–5 of RCM. An FMEA identifies failure modes, their effects, and their consequences — but it doesn't automatically select maintenance tasks. RCM extends the FMEA by adding Questions 6 and 7, which use the FMEA findings to drive a specific maintenance response for each failure mode. RCM without FMEA is incomplete; FMEA without the Q6/Q7 task selection logic produces analysis without action.
Start with assets where failure has the highest safety, environmental, or operational consequences. A simple criticality ranking — scoring assets by failure consequence severity and failure frequency — gives you a prioritized list. In practice, most plants find that 10–20% of their assets account for 80% of their maintenance costs and downtime, so a focused RCM program on those assets delivers most of the value. Use your CMMS downtime and maintenance cost data to build that ranking before the first facilitation session.
Yes — the approach scales down well. Streamlined RCM (sometimes called RCM2 or RCM Blitz) applies the same 7-question logic but focuses only on the top 10–15 critical assets and runs faster facilitation sessions with smaller teams. Even a partial RCM program on your most critical assets will produce better task justification and resource allocation than a schedule built from manufacturer intervals alone.
The 7 questions of RCM give every maintenance decision a defensible, evidence-based rationale — eliminating tasks that aren't justified while ensuring that the failures that actually matter get the right response. The analysis only works, though, if the tasks it produces make it into a system that schedules them, tracks compliance, and captures the reliability data you need to validate and improve the program over time. Cryotos CMMS provides the preventive maintenance scheduling, BI reporting, and asset record structure to turn your RCM analysis into a living maintenance program — not a document that collects dust. Book a free demo to see how Cryotos supports RCM-driven maintenance programs.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











