
Design-out maintenance is a proactive reliability strategy that eliminates recurring equipment failures by making permanent engineering changes to the root cause — rather than scheduling repeated repairs or preventive tasks around a known weakness. Instead of managing a failure mode indefinitely, design-out removes it from the failure population entirely. According to a Plant Engineering maintenance benchmarking study, facilities that apply engineering-driven failure elimination reduce repeat failures on targeted assets by 40–70% within the first 12 months of implementation.
Key Takeaways

Design-out maintenance is the practice of modifying equipment, systems, or operating environments so that a specific failure mode can no longer occur — or occurs so infrequently that it no longer represents a meaningful maintenance burden. It is one of the five maintenance strategy types defined under reliability-centered maintenance (RCM) frameworks, sitting alongside run-to-failure, time-based PM, condition-based monitoring, and predictive maintenance.
The defining characteristic of design-out maintenance is permanence. A corrective repair restores the asset after a failure. A preventive maintenance task delays the next failure. A design-out engineering change removes the failure mode from future consideration entirely. This might mean redesigning a component to use a more durable material, adding redundancy to eliminate a single point of failure, changing operating parameters to keep stresses within safe limits, or replacing a problematic equipment design with a more reliable alternative.
Design-out decisions are typically made at the intersection of reliability engineering and maintenance planning. The maintenance team identifies the pattern — a pump seal that fails every eight weeks despite correct installation and lubrication, for example — and the reliability engineer or engineering team investigates whether a design change can eliminate the failure mode. Common design-out interventions include material upgrades, geometry changes, protective features like guards or drainage, access improvements to reduce error during maintenance, and wholesale equipment replacement where the original design is inherently unreliable.
The cost case for design-out is compelling when you run the numbers. If a recurring failure costs $3,000 per event in labour, parts, and downtime, and it occurs six times per year, that is $18,000 annually — every year — until something changes. A design modification costing $8,000 that eliminates the failure permanently pays for itself in less than six months and continues generating savings indefinitely.
Understanding where design-out fits in the maintenance strategy spectrum helps teams make better decisions about when to apply it versus when a different approach is more appropriate.
| Strategy | How It Addresses the Failure | Ongoing Maintenance Required | Best Applied When |
|---|---|---|---|
| Run-to-Fail | Accepts the failure; repairs after it occurs | Yes — reactive repair every cycle | Low-criticality, cheap-to-replace assets |
| Time-Based PM | Delays failure with scheduled servicing | Yes — recurring task at fixed intervals | Predictable wear patterns, known intervals |
| Condition-Based / Predictive | Detects degradation before failure | Yes — continuous or periodic monitoring | High-criticality assets with measurable degradation signals |
| Design-Out | Eliminates the failure mode permanently | No — failure mode removed from population | Recurring failures where engineering change is cost-justified |
The key difference between design-out and all other strategies is that it is the only one that does not require ongoing maintenance effort for the targeted failure mode. Every other strategy is a management approach — you manage the failure into the future. Design-out is an elimination approach — you engineer the failure out of existence.
This also explains why design-out is not appropriate for every failure mode. It requires an upfront investment in engineering analysis and physical modification, which only pays back when the failure is frequent enough, costly enough, or consequential enough to justify that investment. For a bearing that fails once every five years on a non-critical asset, time-based PM is almost always the more economical choice. For a seal that fails every six weeks on a critical production pump, design-out is worth investigating seriously.
Not every recurring failure is a design-out candidate. The decision framework starts with four qualifying questions that your maintenance and reliability team should ask before investing in an engineering change process.
The first question is frequency: how often does this failure occur? A failure that recurs three or more times per year on the same asset or asset class is the primary signal. If your CMMS failure history shows a pattern of the same failure mode repeating despite correct repairs and proper PM compliance, the failure is embedded in the design — not in the maintenance execution.
The second question is consequence: what does each occurrence cost? Calculate the full cost of the failure, including downtime, labour, parts, production loss, and any safety or compliance implications. Use your MTBF data to project the annual cost of continuing the current approach. If that annual cost significantly exceeds what a design change would cost, the economics support a design-out investigation.
The third question is root cause confidence: do you understand why the failure keeps occurring? Design-out only makes sense when the root cause is clearly identified. If the root cause is still uncertain — or if it varies between occurrences — more root cause analysis is needed before any engineering change is justified. An engineering change applied to the wrong root cause will not eliminate the failure and may introduce new problems.
The fourth question is engineering feasibility: is a design change actually possible? Some failure modes are inherent to the technology and cannot be engineered out without replacing the entire asset. Others have straightforward solutions. A feasibility check with your engineering team or the OEM is the final gate before committing to a design-out project.
Industries where design-out maintenance delivers the highest impact include manufacturing (recurring wear patterns on production line equipment), oil and gas (seal and valve failures in harsh operating environments), food and beverage (hygiene-critical failures that cannot be tolerated repeatedly), and utilities (single-point failures with high consequence in power generation or water treatment). According to Reliabilityweb's RCM framework guidance, design-out is the preferred strategy when no preventive task can effectively manage the failure consequence at a reasonable cost.
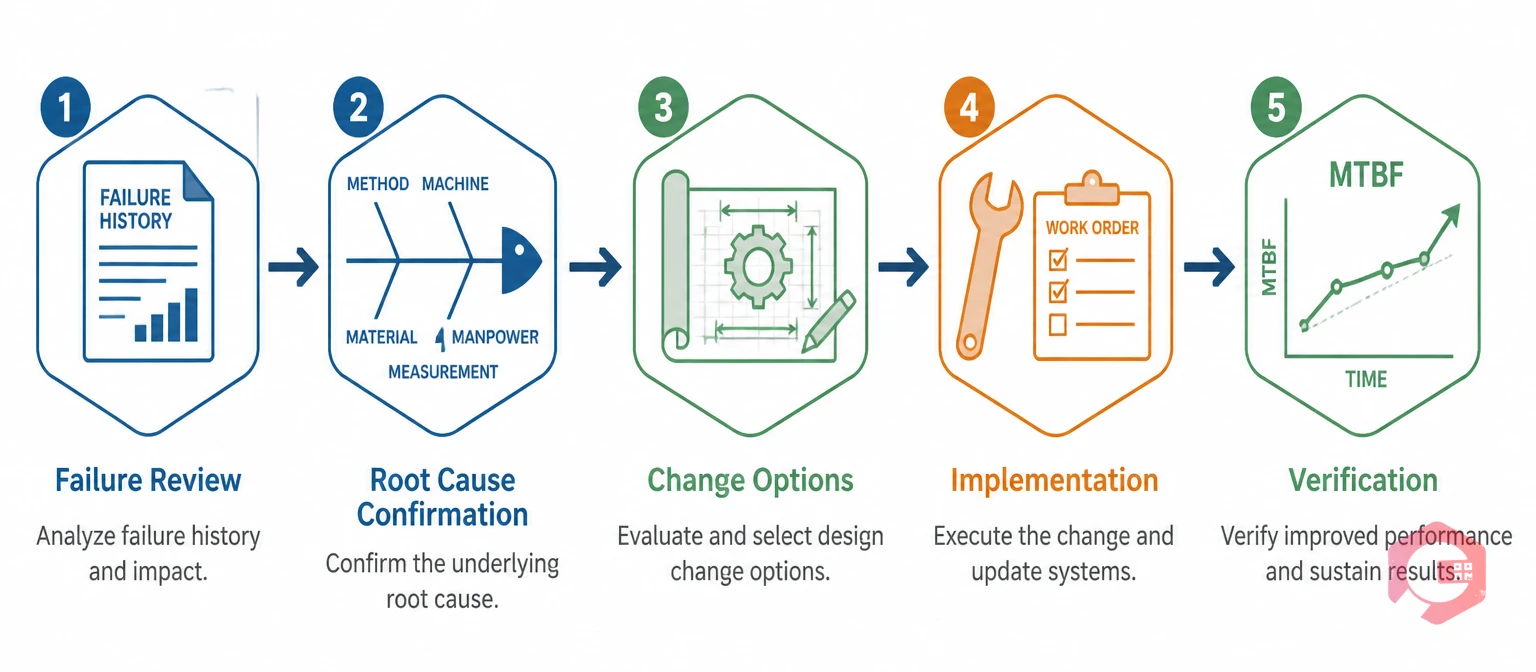
A design-out project follows a structured process that moves from failure identification through engineering change implementation to verification. Skipping steps is the most common reason design-out projects fail to eliminate the failure mode they were intended to address.
The process begins with a formal failure review triggered by a recurring failure threshold — typically three or more occurrences within a 12-month period on the same asset or asset class. The maintenance supervisor or reliability engineer reviews the failure history from the CMMS and confirms that each occurrence represents the same failure mode, not different failure modes in the same component.
Next comes root cause confirmation. The team uses a structured root cause analysis methodology — 5 Whys, fishbone analysis, or a formal FMEA review — to establish the physical, human, and latent causes of the recurring failure. This step is non-negotiable. The engineering change must address the verified root cause, not just the most obvious symptom. A root cause analysis conducted without the full failure history from the CMMS will miss patterns that only become visible when you look across all occurrences together.
With the root cause confirmed, the engineering team develops one or more change options. Each option should be evaluated against three criteria: technical feasibility (can it be implemented with available skills and resources?), reliability improvement (does it address the verified root cause?), and cost justification (does the investment pay back within a reasonable timeframe given the current failure cost?). Multiple options are normal at this stage — the best option is not always the most technically elegant one.
Once an option is selected, the change is implemented as a formal engineering change order and tracked through the maintenance system as a project work order. This creates the documentation trail that proves the change was implemented, when it was completed, who did the work, and what the change consisted of. After implementation, the CMMS failure history and MTBF trend for the affected asset should be monitored for a minimum of 12 months to verify that the failure mode has been eliminated or substantially reduced. If the failure recurs, the root cause analysis was incomplete and the process returns to the investigation stage.
Failure Mode and Effects Analysis (FMEA) and root cause analysis are the two primary diagnostic tools that surface design-out opportunities systematically rather than waiting for failures to become obvious through repeated cost and downtime.
FMEA is a proactive approach, typically applied during equipment commissioning or as part of a periodic reliability review. For each asset, the FMEA team identifies every potential failure mode, its cause, its effect on operations, and the current controls in place to prevent or detect it. The output is a Risk Priority Number (RPN) for each failure mode — a product of severity, probability of occurrence, and detectability. Failure modes with high RPNs are prioritised for risk reduction, and for those where no preventive task can adequately reduce the risk, design-out is the recommended strategy.
Root cause analysis is the reactive complement — applied after a failure occurs to understand why it happened and what systemic condition allowed it. Where FMEA identifies potential design-out candidates before failures occur, RCA identifies them after repeat failures confirm that the current design cannot be maintained reliably. The most valuable RCA outputs for design-out decisions are not the immediate cause (the failed component) but the root cause (the condition that made failure inevitable) and the contributing causes (the systemic factors that allowed the condition to persist).
The practical connection between FMEA, RCA, and design-out works like this: FMEA flags a high-RPN failure mode during commissioning and recommends a design change that the engineering team defers due to cost. The failure eventually occurs, triggering an RCA. The RCA confirms the original FMEA finding and produces an updated cost case — now supported by actual failure cost data rather than estimates. With that data, the design-out business case is approved, the engineering change is made, and the failure mode is eliminated. Both tools inform the same decision; FMEA gets there earlier, RCA gets there with real numbers.
The most instructive design-out cases share a common pattern: a failure that was being managed through repeated corrective repair or frequent PM, a root cause that pointed to a design or installation characteristic, and an engineering change that eliminated the failure mode completely.
In a food and beverage packaging operation, a sealing jaw assembly on a flow-wrapper was failing on average every five weeks due to bearing contamination. The maintenance team had increased PM frequency, used premium bearings, and improved lubrication procedures — and the failure rate barely changed. An FMEA review identified that the bearing housing design allowed cleaning fluids to pool directly above the bearing seal during washdown. The design-out change was a simple drain channel modification to the housing, fabricated and installed in a planned shutdown window. In the 18 months following the change, the failure mode did not recur. The annual maintenance saving was over $40,000 in parts, labour, and unplanned downtime.
In a manufacturing plant, a pneumatic actuator on a critical valve was failing every 10–12 weeks with internal seal deterioration. RCA showed the actuator was being exposed to process gases that were incompatible with the standard seal material — a design specification mismatch between the original plant design and actual operating conditions. The design-out solution was replacing all actuators on that valve bank with units specified for chemical compatibility. Material cost was $12,000; the previous annual failure cost was over $35,000.
In an oil and gas facility, a centrifugal pump impeller was experiencing cavitation damage on a recurring cycle, with replacement every 3–4 months. Condition-based monitoring had been added, but it only detected the damage after it had already progressed to a replacement-requiring stage. The FMEA review confirmed the pump was consistently operating at the left edge of its performance curve — a hydraulic design mismatch with the system. The design-out solution was replacing the impeller with a wider-passage design better matched to the actual flow conditions. Impeller replacement intervals extended from 3–4 months to over 18 months, eliminating 4–5 unplanned events per year.
What these examples share is that none of the failures were random or unpredictable. Each had an identifiable root cause in the design that no amount of conventional maintenance could permanently address. The design change was the only intervention that actually solved the problem.

A CMMS (Computerized Maintenance Management System) is the operational backbone of any effective design-out program. Without it, the data needed to identify design-out candidates, justify the engineering investment, and verify the outcome simply does not exist in a usable form.
The first contribution of a CMMS is failure history capture. For design-out to work, every occurrence of a failure mode must be recorded against the specific asset, with consistent failure codes, root cause findings, parts used, labour time, and downtime duration. Without this discipline, the pattern of recurring failures is invisible — maintenance teams respond to each occurrence as if it were isolated, and the cumulative cost case for a design-out investment is never built. Cryotos's work order management software captures all of this automatically when technicians close work orders on mobile — making failure history the natural byproduct of normal maintenance operations rather than a separate data-entry burden.
The second contribution is pattern identification. When failure codes and asset IDs are captured consistently, your CMMS reporting tools surface repeat failure patterns across assets, sites, and time periods. A maintenance manager reviewing the monthly report and seeing six closed work orders with the same failure code on the same asset class in the past year has exactly the trigger they need to initiate a design-out investigation. Without this visibility, that pattern might take years to become obvious — and the cumulative cost in the meantime is entirely avoidable.
The third contribution is engineering change tracking. A design-out project involves multiple stages — failure review, root cause analysis, engineering change development, implementation, and verification. Each stage should be tracked as a linked work order or project task in the CMMS, creating an unbroken audit trail from the initial failure trigger to the verified outcome. This documentation is valuable for regulatory compliance, insurance purposes, and institutional knowledge retention when team members change.
The fourth contribution is outcome verification. After an engineering change is implemented, the CMMS provides the post-change failure history and MTBF trend that confirms whether the design-out was successful. Cryotos's BI Dashboard tracks MTBF, downtime, and failure frequency per asset in real time, so the improvement — or the persistence of the problem — becomes visible within weeks, not after a year-end review.
Cryotos also supports the IoT integration that makes condition monitoring and failure detection faster, using IoT meter reading to capture operating data that feeds both FMEA analysis and post-change verification. For organisations running formal enterprise asset management programs, design-out maintenance data from Cryotos integrates directly with broader lifecycle cost and capital planning decisions — making the case for engineering investment visible to finance and operations leadership in the language they use.
According to ISO 55000 asset management standards, effective asset management requires balancing cost, risk, and performance across the asset lifecycle — exactly the calculation that design-out maintenance optimises. Teams that apply design-out systematically, supported by complete failure data from a CMMS, consistently achieve lower lifecycle maintenance costs and higher asset availability than those relying purely on reactive repair or fixed PM schedules.
Design-out maintenance is a reliability strategy that eliminates recurring equipment failure modes through permanent engineering changes rather than managing them through ongoing repair or preventive maintenance. It is triggered by failure patterns that persist despite conventional maintenance intervention and targets the verified root cause of those patterns through modifications to equipment design, materials, installation, or operating conditions.
Design-out is the better choice when a failure mode recurs three or more times per year despite correct preventive maintenance execution, when the annual cost of managing the failure exceeds the cost of an engineering change that would eliminate it, and when root cause analysis has confirmed a design, material, or specification deficiency that no PM task can adequately address. If a PM task can manage the failure mode reliably at a lower cost than a design change, time-based or condition-based maintenance remains the appropriate strategy.
Root cause analysis is a diagnostic process used to identify why a failure occurred. Design-out maintenance is the corrective strategy applied when RCA reveals a root cause that can only be addressed by modifying the equipment or system design. RCA identifies the problem; design-out solves it permanently. In practice, RCA is the primary trigger for most design-out projects — a completed RCA that points to an inherent design deficiency is the strongest justification for initiating an engineering change.
FMEA (Failure Mode and Effects Analysis) identifies potential failure modes before they occur and prioritises them by risk. For failure modes that score high on severity and occurrence but cannot be adequately controlled by available maintenance tasks, FMEA explicitly recommends design changes as the preferred risk mitigation. This makes FMEA both a proactive screening tool that surfaces design-out candidates during commissioning and a structured validation tool that confirms the design deficiency identified by post-failure RCA.
A CMMS supports design-out maintenance by capturing the failure history that surfaces recurring patterns, providing MTBF and downtime data that builds the economic case for engineering investment, tracking engineering change projects through the implementation process, and verifying post-change outcomes through before-and-after reliability metrics. Without consistent CMMS data, most design-out opportunities remain invisible until their cumulative cost becomes unmistakable — years after the pattern was first detectable.
If your team is repeatedly fixing the same failures without permanent results, the problem is not your maintenance execution — it is the design. Cryotos gives maintenance and reliability teams the failure history, MTBF trending, and work order tracking needed to identify design-out candidates, build the engineering change business case, and verify that the changes actually work. Schedule a free demo and see how leading maintenance teams use data-driven failure analysis to turn recurring breakdowns into permanent reliability improvements.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











