
When production runs at a constant surge for two weeks to meet a customer deadline and then drops to near-idle while orders are processed, the maintenance team doesn't experience two weeks of heavy production followed by a quiet period. They experience two weeks of accelerated equipment wear followed by a peak in reactive work orders — breakdowns, bearing failures, motor faults, and hydraulic leaks — precisely when the production team wants to restart at full capacity. The production spike and the maintenance crisis are the same event, seen from two departments. Heijunka — the Toyota Production System concept of production leveling — is the practice that prevents the spike from occurring, and in doing so, stabilises the downstream maintenance demand that spikes create. According to the Toyota Production System framework, Heijunka is one of the foundational mechanisms for eliminating Mura (unevenness) — and in maintenance, unevenness in production is one of the most consistent upstream drivers of reactive failure.
This guide covers what Heijunka means in both production and maintenance contexts, how unleveled production creates unleveled maintenance demand, how Heijunka principles apply to maintenance scheduling directly, and how a CMMS supports workload leveling in practice.

Heijunka (平準化) translates as "levelise" or "production leveling" — the practice of smoothing the volume and mix of production output over a defined period rather than producing to the rhythm of customer orders as they arrive. In a leveled operation, the same number of units of the same mix of products is produced each day, each shift, each week — regardless of the pattern in which orders arrive. Customer demand variation is absorbed by inventory buffers at the output end; the production process itself runs at a stable, predictable pace.
For maintenance, this stable pace matters enormously. Equipment that runs at a consistent duty cycle wears in a predictable pattern that PM schedules can be calibrated to. Equipment that surges to 140% capacity for two weeks and then idles for five days wears non-linearly — faster during surges, with residual damage that manifests as failures during the idle period or the next production ramp. Heijunka doesn't just help production planning; it makes maintenance planning possible.
Heijunka operates across two dimensions. Volume leveling means producing the same total quantity each period. Mix leveling means producing the same proportional mix of product types each period, rather than batching — all of Product A this week, all of Product B next week. Both dimensions have maintenance implications.
Volume leveling directly reduces the surge-and-idle equipment stress pattern. Mix leveling has a subtler effect: when the product mix changes week to week, machine changeovers increase and different asset types bear the load in different periods. A maintenance team planning PM for a dedicated Product A line can calibrate schedules to Product A's duty cycle; a maintenance team serving a line that runs Product A for a month and then switches to Product B faces a different equipment stress profile each production cycle. Mix leveling stabilises the stress profile alongside the volume, making PM calibration reliable rather than approximate.
The three M's of the Toyota Production System — Mura (unevenness), Muri (overburden), and Muda (waste) — translate directly into maintenance pathology when production runs without Heijunka.
Mura in maintenance is the uneven demand pattern: too many reactive work orders this week, idle capacity next week, a PM backlog that grows during surge periods and gets rushed through during quiet periods. Muri in maintenance is equipment overburden — assets running above their designed duty cycle during production surges, accumulating stress faster than their PM schedule assumes. Muda in maintenance is the waste that Mura and Muri generate: emergency parts purchases at premium prices, overtime for technicians responding to surge-driven breakdowns, diagnostic time spent on failures that adequate PM during a leveled cycle would have prevented. Heijunka addresses the Mura at source, which reduces the Muri, which reduces the Muda.
The relationship between production variability and maintenance demand is causal, not coincidental. Understanding the mechanism is what allows maintenance managers to make the case for production leveling in cross-functional conversations — and to quantify the maintenance cost of unleveled schedules in terms that production managers respond to.
Equipment failure probability increases non-linearly with operating intensity. A conveyor running at 110% of rated speed doesn't fail 10% faster than one running at rated speed — it may fail several times faster, depending on the component and the failure mode. When production runs a surge cycle, the peak operating intensity during the surge period compounds wear on bearings, seals, motors, and drive components. This accelerated wear doesn't always result in immediate failure during the surge — the failure may occur during the subsequent trough when the equipment restarts after an idle period, when thermal cycling during shutdown causes already-degraded seals to leak, or when the next production ramp reveals that bearings that barely survived the last surge cannot survive another.
The result is a failure pattern that lags the production surge by days to weeks — the reactive maintenance peak arrives after the production crisis, not during it. From the maintenance team's perspective, this pattern is confusing: breakdowns cluster in periods when production isn't obviously stressing the equipment. From the Heijunka perspective, the cause is clear: the previous surge loaded the failure queue; the trough triggered the release.
When production runs overtime to meet a deadline — additional shifts, reduced changeover time, deferred minor stoppages — maintenance bears a cost that never appears in the overtime budget. Deferred minor stoppages are deferred maintenance interventions: the oil level that wasn't checked because the line couldn't stop, the abnormal noise that was noted but not acted on, the filter change that was pushed to the following week. Each deferral is a compounding liability that will surface as a reactive work order when the overtime schedule ends.
According to the Lean Enterprise Institute, the total cost of a breakdown typically runs 5–10 times the cost of the preventive maintenance that would have prevented it — accounting for emergency parts procurement, technician overtime, production loss during repair, and quality losses from the restart. Tracking maintenance work order costs by production schedule period — leveled vs. surge — makes this relationship visible and provides the data for cross-functional conversations about scheduling decisions and their true total cost.
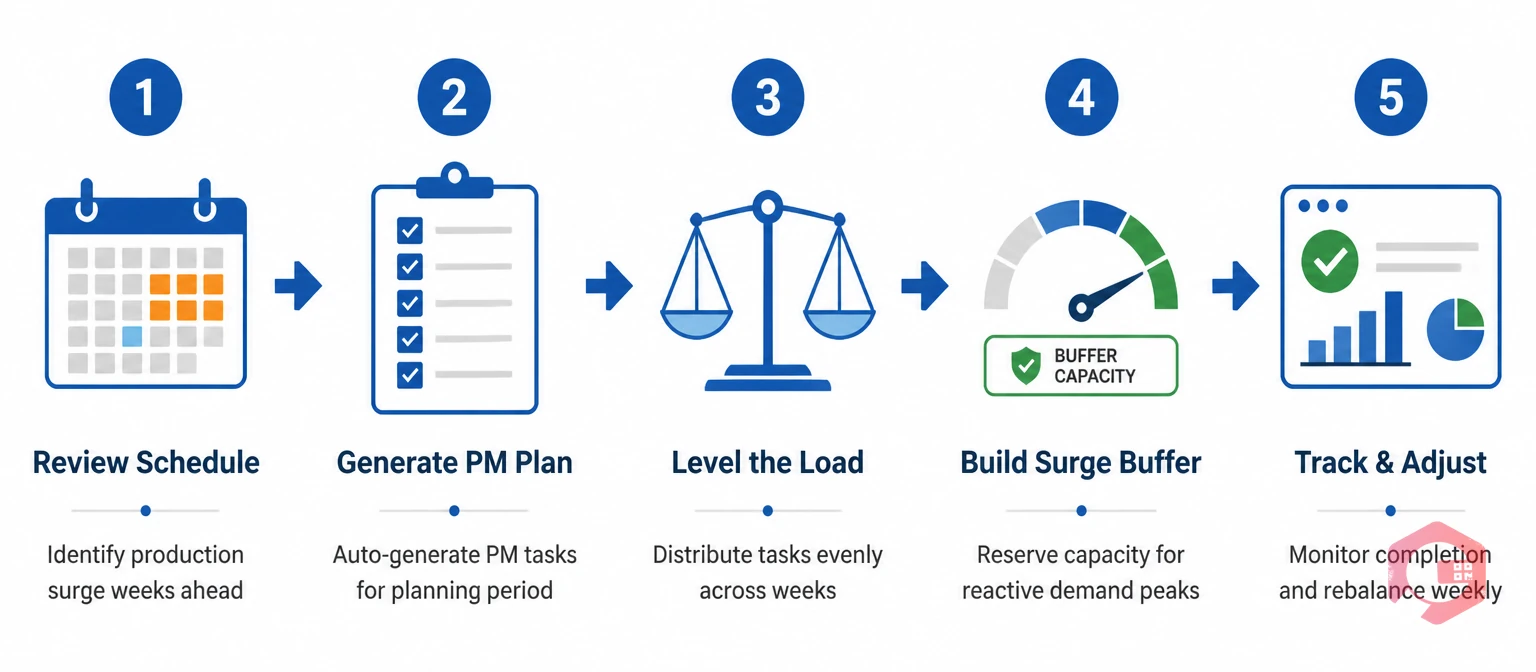
Heijunka is not only a production concept. Its logic — smooth the workload over time, avoid peaks and troughs, run at a stable pace — applies directly to how maintenance work is scheduled. A maintenance team that plans PM tasks in batches (all HVAC PMs in the first week of the month, all electrical PMs in week three) creates its own internal Mura. Technicians are overloaded in PM weeks and underloaded in reactive-only weeks, parts consumption spikes in PM batch weeks and drops in others, and the reactive work that arrives on top of a PM batch week creates exactly the overburden that Heijunka is designed to prevent.
Applying Heijunka to PM scheduling means distributing planned maintenance tasks evenly across available time, rather than batching by asset type, location, or administrative convenience. A monthly PM schedule with 60 tasks should aim to distribute them as 15 per week, or 3 per day in a 5-day week — not as 40 tasks in the first two weeks and 20 in the last two. The level schedule absorbs reactive demand variation more gracefully because there is consistent uncommitted capacity each week to handle the unexpected, rather than a backlog of deferred PMs competing with reactive work in the same window.
The preventive maintenance software module generates PM schedules automatically — but the maintenance manager's role is to review the generated schedule for Heijunka: are tasks distributed evenly, or do they cluster in certain weeks? Are certain technicians carrying three times the PM load of others in the same period? The CMMS generates the schedule; Heijunka thinking ensures the schedule is leveled before it is issued.
Reactive maintenance demand is by definition unpredictable at the individual work order level — you cannot know in advance which specific asset will fail on which day. But at the aggregate level, reactive demand has patterns. Assets with insufficient PM coverage generate more reactive work. Assets running above designed duty cycle during production surges generate reactive spikes at known lag times after surges. A CMMS that captures work order history, PM completion rates, and production schedule data gives maintenance managers the forecast inputs to anticipate reactive demand increases and pre-position resources — rather than responding to each reactive spike as if it were the first time the pattern had appeared.
This is Heijunka applied to reactive maintenance: not eliminating the reactive demand, but anticipating it well enough to absorb it within a leveled total workload rather than allowing it to create a crisis that disrupts the entire week's planned schedule.
The operational difference between a Heijunka-leveled maintenance operation and an unleveled one is visible across every dimension of the maintenance team's experience and performance data:
| Dimension | Unleveled Workload | Heijunka-Leveled Workload |
|---|---|---|
| PM completion rate | High in quiet weeks; drops during surge periods when reactive work dominates | Consistent 85–95% across all weeks; reactive demand absorbed without displacing PMs |
| Reactive work order volume | Spikes 2–4 weeks after production surges; creates crisis-response mode | Stable baseline with predictable variation; no surge-driven spike pattern |
| Parts inventory | Emergency procurement spikes during reactive peaks; overstock after surge periods | Predictable consumption; standard reorder cycle without emergency orders |
| Technician utilisation | Overloaded during reactive peaks; underloaded in quiet periods | Consistent 75–85% utilisation; capacity available for both planned and reactive work |
| Mean Time Between Failures | Decreases during and after production surges; PM calibration breaks down | Stable MTBF aligned with PM intervals; PM calibration remains accurate |
| Maintenance cost per unit produced | Higher — emergency premiums, overtime, quality losses from breakdown repairs | Lower — PM-dominant programme; predictable parts and labour costs |
The leveled column is not a theoretical ideal — it is the observable outcome for maintenance teams whose production operations run with Heijunka discipline and whose maintenance scheduling is reviewed for workload distribution before each planning period. The unleveled column is the experience of maintenance teams managing the consequences of production decisions they had no input into.

A CMMS supports Heijunka in maintenance operations at two levels: the visibility level and the scheduling level. At the visibility level, the CMMS makes the production-maintenance demand relationship visible in data — work order volumes by week, reactive vs. planned ratios over time, MTBF trends correlated with production intensity periods. This data turns the connection between production variability and maintenance demand from an intuition into a measurable relationship that can be presented in cross-functional planning meetings.
At the scheduling level, the CMMS generates PM schedules and work order queues that the maintenance manager can review for Heijunka — identifying weeks where the planned workload significantly exceeds or falls below the team's capacity, and rescheduling to distribute the load more evenly. The BI Dashboard visualises weekly workload distribution — total planned hours by technician, by team, and by asset category — giving the maintenance manager the overview needed to identify imbalances before the schedule is issued rather than discovering overload during execution.
For operations where production scheduling data is available from an ERP or MES, CMMS integration allows maintenance teams to receive production schedule visibility in advance — seeing peak production weeks approaching and pre-positioning PM completion, parts stock, and technician availability accordingly. This is the most mature form of Heijunka-aware maintenance management: not reacting to production surges after they create maintenance demand, but anticipating them and absorbing them proactively.
Cryotos CMMS gives maintenance managers the scheduling, visibility, and reporting tools to apply Heijunka thinking to their operations regardless of whether the production team has formally adopted leveling. The PM scheduling module generates task lists across the planning period and allows managers to review distribution by week, by technician, and by asset category before approving the schedule — giving a Heijunka review step before deployment rather than after.
The work order management software tracks actual workload against planned workload in real time — surfacing weeks where reactive demand has displaced planned work and the PM schedule is falling behind. This early warning gives maintenance managers the data to make scheduling adjustments before a PM backlog accumulates to the point where the next reactive surge finds the team already overloaded.
The Report Builder generates workload distribution reports by period — showing reactive vs. planned work ratios, PM completion rates by week, and technician utilisation trends — making the Heijunka analysis of the maintenance operation an ongoing monthly discipline rather than an annual review. Cross-functional reports that correlate maintenance reactive volumes with production schedule intensity give operations directors the data to make production scheduling decisions with maintenance cost visibility included. Teams using Cryotos report a 30% reduction in unplanned downtime, with maintenance workload leveling and improved PM completion consistency cited as significant contributors in operations where Heijunka principles have been applied to both production and maintenance scheduling.
Heijunka in maintenance management refers to two related applications of the production leveling principle. First, it describes how leveled production schedules stabilise downstream maintenance demand — by eliminating production surges that overburden equipment and create reactive failure patterns. Second, it describes the direct application of leveling logic to maintenance scheduling itself: distributing PM tasks, inspections, and planned work evenly across the planning period to avoid creating internal peaks and troughs in the maintenance team's workload. Both applications reduce the reactive maintenance burden — the first by controlling the upstream driver of reactive demand, the second by ensuring the maintenance team has consistent capacity to absorb reactive work without disrupting planned activities.
Production leveling reduces reactive maintenance through two mechanisms. First, by eliminating equipment overburden during production surges — assets running at or below their designed duty cycle consistently wear in a predictable pattern that PM schedules can reliably prevent. Second, by eliminating the deferral of minor maintenance interventions that accumulate during rush production periods. When production runs at a stable pace, small issues get addressed at the point of observation rather than deferred because the line cannot stop. The cumulative effect of these two mechanisms is a significantly lower reactive work order rate — assets don't fail at surge-driven peaks, and defect backlogs don't accumulate during rush periods to surface as breakdowns when the pressure eases.
Yes — a CMMS supports Heijunka maintenance scheduling through PM schedule generation and workload distribution review. The CMMS generates the task list for the planning period; the maintenance manager reviews it for workload distribution across weeks and technicians, identifies imbalances, and adjusts task scheduling to level the load before issuing the plan. Some CMMS platforms include capacity planning views that show planned hours by week explicitly, making the Heijunka review straightforward. The CMMS also supports reactive demand forecasting by surfacing historical patterns — which asset categories and production intensity periods generate the most reactive work — allowing the maintenance manager to build buffer capacity into high-risk periods rather than discovering the overload when it arrives.
Mura (unevenness) in maintenance is the variability in workload — weeks with excessive reactive demand alternating with weeks of underutilisation, PM completion rates that swing from 95% in quiet weeks to 40% in surge weeks, parts consumption that spikes and troughs unpredictably. Muri (overburden) in maintenance is the equipment overloading that occurs when production surges push assets above their designed operating intensity, and the technician overloading that occurs when reactive demand peaks compress the same team that is also trying to complete a PM backlog. Muda (waste) is the financial and operational waste that Mura and Muri generate: emergency parts orders at premium pricing, technician overtime for breakdown response, quality losses from assets repaired under time pressure, and the diagnostic effort spent on failures that structured PM would have prevented. Heijunka targets Mura; reducing Mura naturally reduces Muri and Muda downstream.
The maintenance crisis that follows a production rush is not bad luck. It is the predictable consequence of Mura — unevenness — flowing through the production system and expressing itself as equipment stress, deferred maintenance, and reactive failure clusters. Heijunka addresses the root of that pattern at the production scheduling level, and maintenance scheduling Heijunka addresses the same logic internally — distributing the maintenance team's planned work at a pace that keeps consistent capacity available for the reactive demand that even well-leveled operations occasionally generate.
For maintenance managers ready to move from reactive crisis management to Heijunka-informed scheduling, Cryotos CMMS provides the PM scheduling, workload visibility, and reporting tools to review, distribute, and track maintenance work at a level pace. Book a free demo today and see what your maintenance workload looks like when you stop letting the production calendar decide it for you.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











