
Equipment incident reporting in a CMMS connects the moment a fault occurs to the people, parts, and data needed to fix it — and prevent it from recurring. Without a structured system, incidents get scrawled on paper, relayed informally between shifts, or simply forgotten. Cryotos gives maintenance teams a mobile-first, structured way to capture equipment incidents the moment they happen and convert that data into reliability analytics, corrective work orders, and compliance records.
This guide explains how Cryotos handles every stage of incident capture and reporting — from a technician scanning a QR code on the shop floor to a manager reviewing MTBF trends across an entire equipment class.
Key Takeaways
Equipment incident reporting is the process of capturing, classifying, and acting on any unplanned event that causes or could cause a breakdown, safety risk, production loss, or regulatory exposure. This covers sudden mechanical failures, abnormal vibrations, leaks, electrical faults, and near-misses — anything that deviates from normal operating conditions and demands a documented response.
A Computerized Maintenance Management System turns incident reporting from a paperwork exercise into a structured data asset. When an incident is logged in the system, it links immediately to the asset record, the responding technician, the full maintenance history, and the cost centre. That linkage is what makes root cause analysis evidence-based and what gives compliance teams a complete, verifiable audit trail — rather than a folder of handwritten notes.
According to OSHA's recordkeeping requirements, organisations in regulated industries must maintain accurate incident records. A CMMS ensures that standard is met automatically rather than retroactively assembled before an audit.

Paper-based and informal incident reporting creates three critical gaps that compound over time across any maintenance operation.
Maintenance teams using Cryotos have reported up to 30% reduction in unplanned downtime and 25% faster repair turnaround — largely because incidents are captured completely at the point of failure, acted on immediately, and analysed systematically over time.
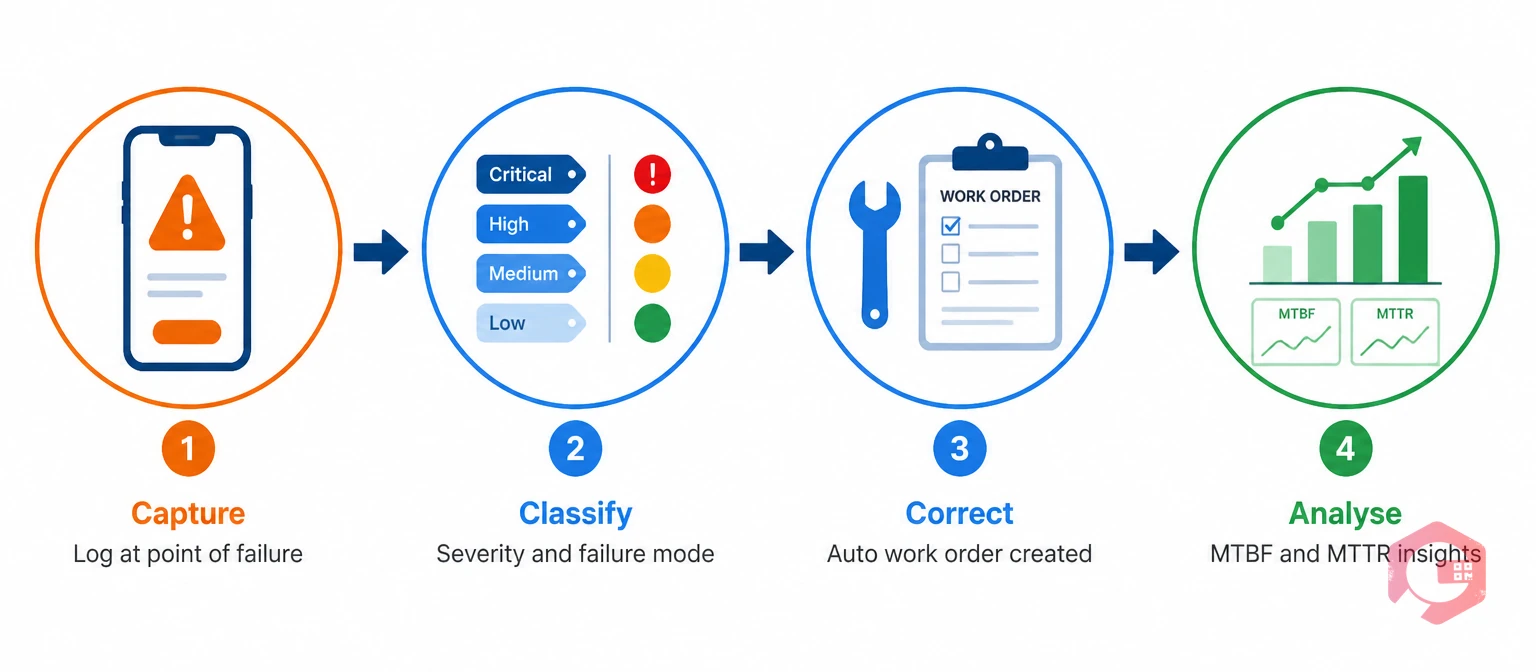
Cryotos is built on the principle that incident capture must happen at the point of failure — not an hour later at a desk. Every feature below is designed to reduce the friction between "technician spots a problem" and "structured data enters the system."
Technicians and operators log equipment incidents directly from the Cryotos mobile app — on the shop floor, in the field, or at a remote site. The app operates in full offline mode with automatic sync, so connectivity gaps do not interrupt incident capture. The asset, incident type, severity, description, timestamp, and location are all recorded without returning to a desk.
Every asset in Cryotos carries a QR or barcode label. Scanning the label loads the full asset record instantly — including maintenance history, open work orders, and a direct shortcut to log a new incident. This eliminates manual asset lookup and ensures every incident is linked to the correct equipment record from the start. Cryotos's asset QR code scanning makes this a one-tap process for any operator with a smartphone.
Incident capture in Cryotos uses structured forms — not free-text notes. Maintenance managers define the fields that matter: fault type, failure mode, affected system, environmental conditions, operator on duty, and production impact. Structured capture means incidents are comparable across teams, sites, and time periods — which is precisely what makes trend analysis actionable rather than anecdotal.
Every incident report supports photo and video attachments. Technicians photograph the failed component, leaking seal, or damaged panel at the moment of the incident. This visual evidence becomes part of the permanent asset record — available to engineers, root cause analysts, and auditors without reconstruction or memory-dependent retelling.
When an incident is logged, Cryotos automatically generates a corrective work order — pre-linked to the asset, pre-populated with incident details, and routed to the right technician based on asset type and skill requirements. Cryotos's work order management system reduces the time from incident to corrective action from hours to minutes, without any manual re-entry.
Each incident is assigned a severity level — critical, high, medium, or low — at the point of capture. Severity drives automatic escalation rules: a critical incident triggers immediate notifications to the maintenance manager and safety officer. Lower-priority incidents queue as planned corrective tasks. The right response happens at the right speed, without a manager manually triaging every incoming report.
Cryotos sends push notifications, SMS alerts, and email escalations when incidents are logged or when response SLAs are approaching breach. No incident sits unacknowledged. Managers see open incidents on their dashboard in real time — not at the morning meeting or shift handover hours later.
Cryotos supports logging near-misses and safety observations using the same structured forms as equipment failures. These are linked to assets and locations, and reported separately from equipment breakdowns. Over time, near-miss data reveals where equipment poses recurring safety risk before a reportable incident occurs — the proactive posture that ISO 55000 asset management standards recommend for mature maintenance programmes.
Already capturing incidents informally? See how Cryotos's downtime tracking module converts those records into reliability metrics your operations team can act on.
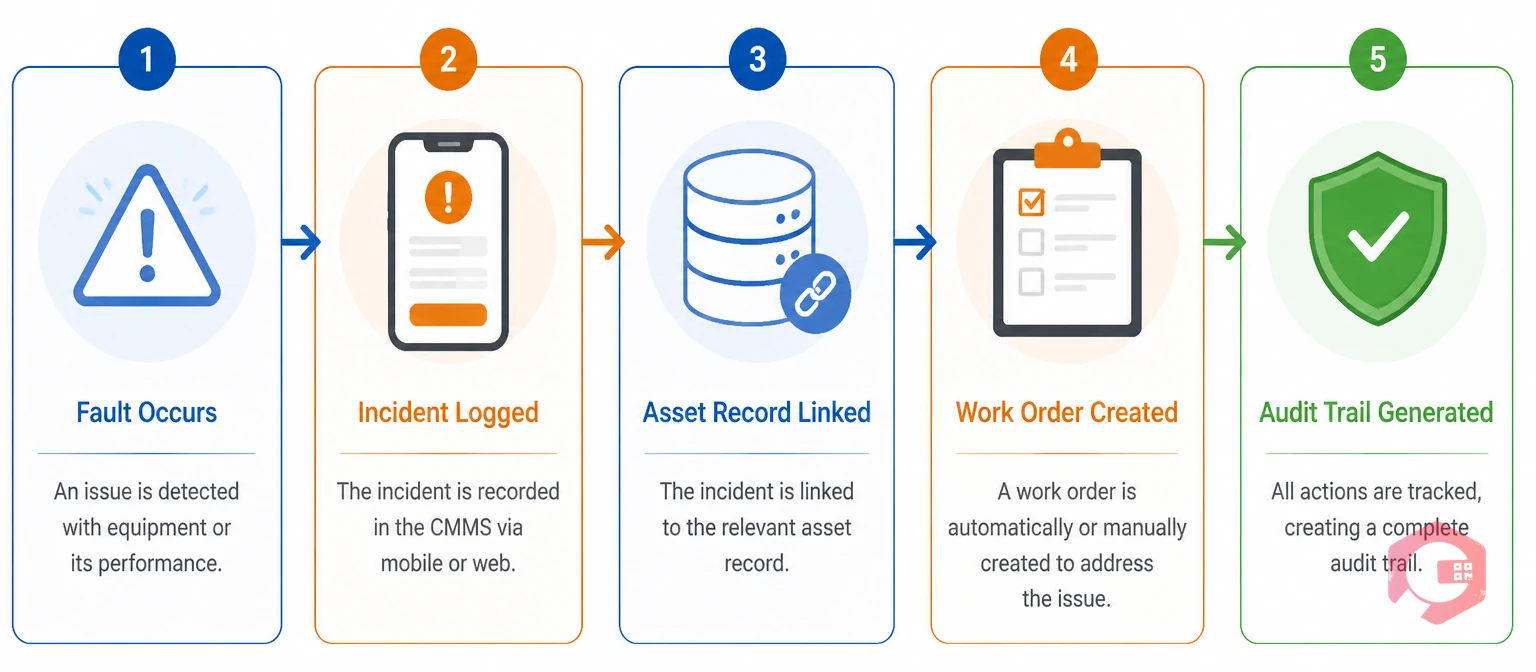
Most maintenance teams manage the first stage of incident handling well — something breaks, someone reports it. The remaining three stages are where structured systems separate high-performing reliability programmes from operations stuck in a reactive cycle.
The Cryotos Incident Lifecycle Framework:
This cycle mirrors the corrective maintenance standards recommended by the Society for Maintenance and Reliability Professionals (SMRP), with the advantage that Cryotos automates the transitions between stages rather than relying on manual handoffs between shifts or departments.

Once incidents are captured in Cryotos, they stop being a log of things that went wrong and become the foundation for decisions about what to change. This is where structured incident reporting delivers its highest return.
Every incident is linked to the asset's complete maintenance history — past work orders, previous failures, parts replaced, and PM intervals. When a technician investigates a recurring failure, the full timeline is already assembled in Cryotos. Root cause analysis is evidence-based rather than memory-based, which means findings are defensible and corrective actions are tracked to confirmed closure — not just assigned and forgotten.
Cryotos calculates Mean Time Between Failures (MTBF) and Mean Time To Repair (MTTR) automatically from incident and work order data. Managers see reliability performance at the individual asset level and across entire equipment classes. Use the MTBF calculator to benchmark current performance before implementing structured incident reporting — the improvement is measurable within weeks once incidents are captured consistently.
Incidents in Cryotos link directly to the downtime tracking module. Each incident causing production loss is tagged with the downtime duration, affected production line, and estimated cost impact. Reports surface downtime by asset, by team, by shift, and by incident type — giving leadership the data to prioritise capital expenditure and maintenance budget allocation based on actual cost rather than operational instinct.
The Cryotos AI dashboard answers plain-language questions: "What was our most common failure mode last month?" or "Which production line had the highest incident rate in Q2?" Teams get chart-based insights without manually querying a database. When five compressors across two sites log the same failure mode at similar intervals, Cryotos surfaces the pattern — so the PM schedule for the entire equipment class is adjusted before a cascade of failures makes the problem impossible to ignore.

Every incident logged in Cryotos is time-stamped, linked to an asset, and associated with the technician who responded — creating an automatic audit trail that satisfies regulatory requirements in food and beverage, pharmaceutical, healthcare, and utilities environments.
Compliance reports are generated from actual system data, not reconstructed from memory before an audit. Audit trails are complete, exportable, and tied to specific work orders and cost data. For industries operating under FDA, ISO, or OSHA frameworks, this removes the pre-audit scramble of locating paper records and reconciling shift logs. The record exists because the incident was captured correctly the first time.
Any unplanned event that causes or could cause a breakdown, safety risk, production loss, or regulatory exposure should be logged. This includes equipment failures, abnormal operating conditions such as unusual vibration, elevated heat, or unexpected noise, leaks, near-misses, and operator-reported faults. The threshold should be low — it is far cheaper to log a false alarm than to miss a precursor to a serious failure that a structured system would have flagged weeks earlier.
When a technician submits an incident report in Cryotos, the system reads the asset type, severity classification, and incident category and generates a corrective work order pre-populated with those details. The work order is automatically routed to the technician or team assigned to that asset class based on skill requirements. No manual data re-entry is required — the incident and the corrective task share the same record from creation through to closure and cost attribution.
Yes. Cryotos supports near-miss and safety observation logging using the same structured forms as equipment incidents, but tags them as a separate incident category so they can be reported and analysed independently. Over time, near-miss patterns reveal recurring safety risks at specific assets or locations before a reportable incident occurs — giving maintenance and safety teams the data to intervene proactively.
Cryotos pulls incident timestamps and work order closure data automatically to calculate MTBF (the average operating time between failures for a given asset) and MTTR (the average time from incident log to confirmed repair completion). Both metrics update in real time as incidents are resolved and are visible at the individual asset level and across equipment classes in the BI dashboard — no manual calculation or spreadsheet exports required.
Structured equipment incident reporting is one of the highest-return changes a maintenance team can make, and Cryotos makes the transition from paper logs to structured data immediate. Schedule a free demo to see how Cryotos captures incidents at the source, drives corrective action without delay, and builds the reliability analytics your operations team needs to make decisions based on evidence.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











