
Mean Time to Repair (MTTR) measures the average time it takes to restore a failed asset to full working condition from the moment a breakdown occurs. To reduce MTTR, maintenance teams need to attack four specific time sinks: detection, dispatch, diagnosis, and repair execution. Organizations that cut MTTR by even 20% report significant gains in equipment availability and measurable cost savings across their operations.
According to the Society for Maintenance and Reliability Professionals, high MTTR is one of the top three contributors to unplanned downtime losses in industrial facilities. The problem is rarely a single bottleneck — it is a chain of delays that compound from the moment a fault occurs to the moment production resumes.
This playbook breaks that chain into six actionable steps you can start implementing this week, with practical guidance at each stage and the metrics to prove it is working.
Key Takeaways
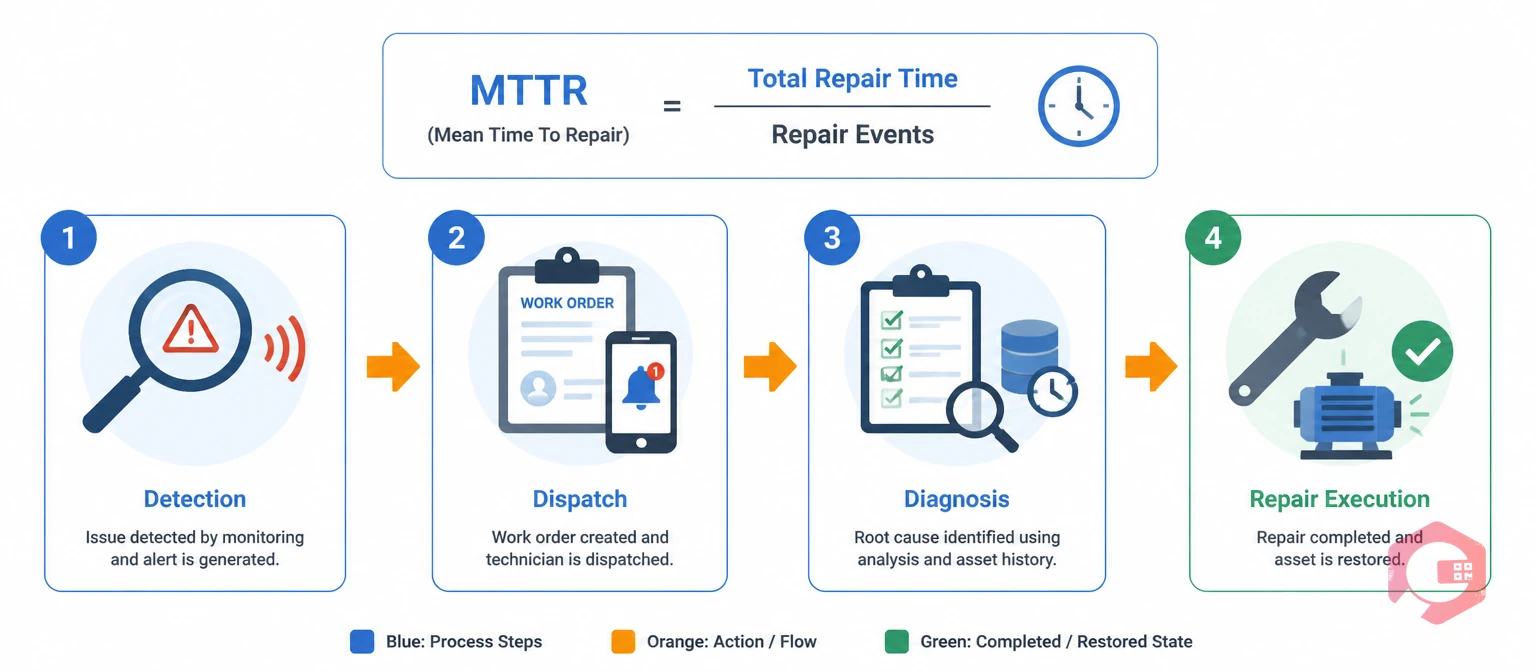
MTTR stands for Mean Time to Repair. The standard formula is straightforward: MTTR = Total Repair Time ÷ Number of Repair Events. If your team spent 12 hours repairing three assets in a week, your MTTR is 4 hours.
That sounds simple, but "repair time" can be defined narrowly (wrench time only) or broadly (from the moment production stopped to the moment it restarted). For operational decision-making, the broader definition is more useful — it captures every delay in your process, not just the time a technician spent turning bolts.
It is worth computing your current baseline before targeting any improvement. Without a measured starting point, you cannot know whether your interventions are working or which step in the repair cycle is costing the most time.

Every hour of unplanned downtime has a direct cost in lost production, emergency labor premiums, and knock-on schedule disruptions. Plant Engineering research consistently places unplanned downtime costs for industrial manufacturers at $250,000 or more per hour when total production impact is fully accounted for.
Beyond the financial impact, high MTTR creates a cycle of reactive firefighting that gradually burns out maintenance teams. Technicians spend their time responding to crises instead of preventing them. Over time, asset condition deteriorates because scheduled work gets displaced by emergency repairs — which makes future failures worse and longer to fix.
MTTR also directly affects your Mean Time Between Failures (MTBF). Teams that focus on MTTR often find MTBF improves in parallel, because faster, better-executed repairs leave assets in better condition than rushed reactive fixes. Use the downtime tracking module in your CMMS to measure how much productive time you are losing per asset each week, and make the true cost visible before prioritizing your improvement effort.
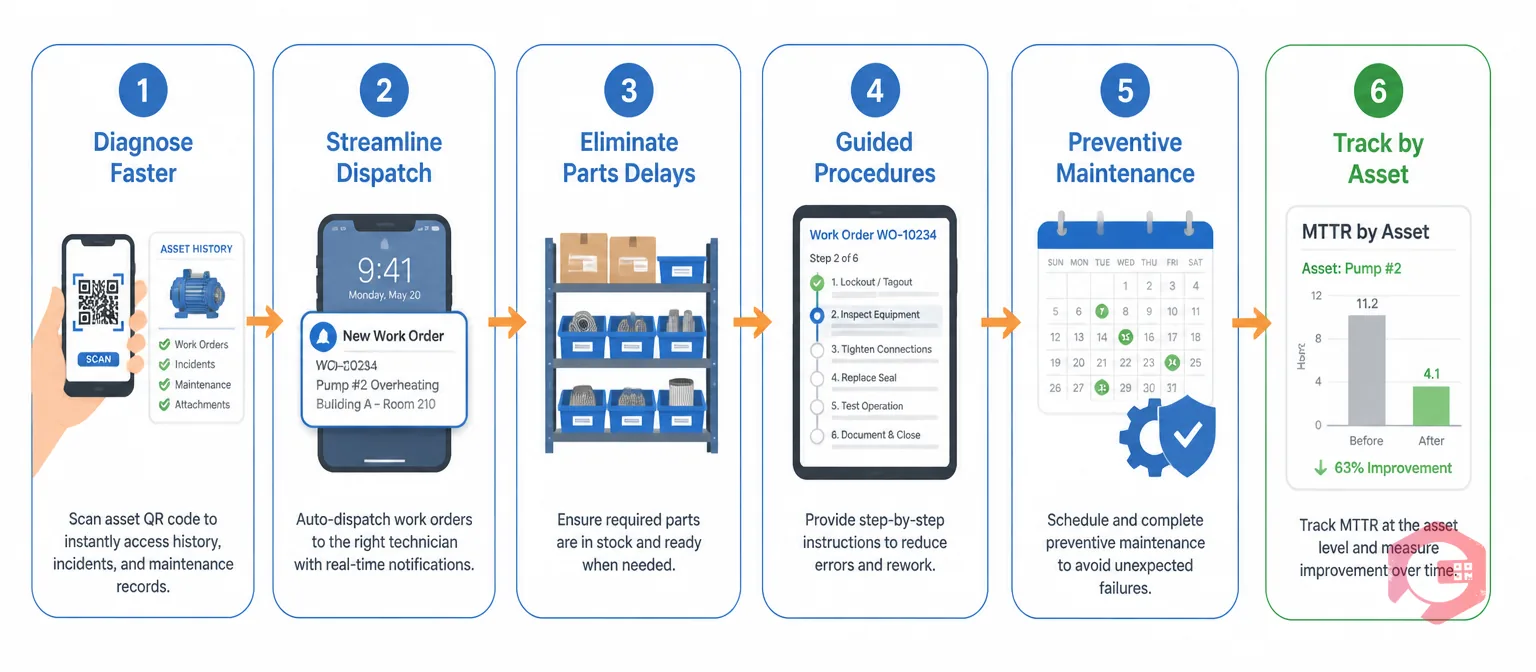
The diagnostic phase — figuring out what is wrong before any repair work begins — often consumes 30 to 50% of total repair time. Technicians arrive at a failed asset with no context, no history, and no repair guidance. They start troubleshooting from scratch every time.
The fix is making asset history, previous failure modes, and maintenance procedures instantly accessible at the point of failure. When a technician can scan a QR code on an asset and pull up its last three repair records, the probable fault narrows immediately. Diagnosis that used to take 45 minutes often takes under 10 when history is searchable and on-hand at the machine.
IoT-connected equipment takes this further. When sensors detect an anomaly — a temperature spike, a vibration shift — the alert can carry the sensor data directly into the work order, so the technician knows the likely fault before leaving the workshop. Cryotos CMMS connects IoT readings to asset records and maintenance history, giving technicians the context they need to diagnose in minutes rather than hours and arrive at the machine with the right part already in hand.
The time between a fault occurring and a technician receiving a work order is dead time. In many facilities this gap runs 20 to 60 minutes — a fault is spotted, someone has to find the maintenance coordinator, the coordinator has to create a work order, and a technician has to be located and briefed. The machine has been offline for an hour before any repair work has started.
Automated dispatch eliminates that gap. When an operator scans a QR code to report a fault or an IoT sensor triggers an alert, the system creates and assigns a work order in seconds. The technician receives it on their mobile device with all relevant asset information already attached. Response time drops from 30–60 minutes to under 5.
Effective work order management also solves the prioritization problem. Without a system, the loudest complaint gets the fastest response — not the most operationally critical failure. Automated priority routing ensures critical assets get a technician first, every time, without a coordinator making judgment calls under pressure.
Use the MTTR calculator to establish your baseline before implementing any of the steps below. Even a 15-minute reduction in dispatch time translates to meaningful MTTR gains across dozens of repair events per month.

Across maintenance operations, parts availability is the most commonly cited cause of extended MTTR. A technician arrives at a failed asset, diagnoses the fault in 20 minutes, and then spends 4 hours waiting for the correct spare to arrive from another site or be expedited from a supplier. The repair itself takes 30 minutes. The MTTR for that job is nearly 5 hours, with 80% of that time sitting in a parts delay.
The solution is not to stockpile everything — excess inventory carries its own cost burden. The solution is visibility: knowing exactly what is in stock, where it is, and which assets it serves. Effective inventory management links spare parts directly to asset records and sets minimum-stock alerts for critical components. When stock drops below the configured threshold, the system triggers a replenishment request before a breakdown forces a scramble.
Cryotos maps warehouse inventory down to aisle, rack, and bin — so when a work order is created for a failing pump, the system shows the technician exactly which shelf holds the required seal kit. Every minute spent searching the storeroom is a minute added to MTTR that a well-organized inventory system eliminates entirely.
Even experienced technicians repair equipment more slowly when they are unfamiliar with a specific asset. Skill gaps are a significant MTTR driver in facilities with large or diverse asset bases — one technician might be expert on the hydraulic press but slower on the packaging line's servo drives. The gap widens further when contractors perform repairs on equipment they have never seen before.
Digital, step-by-step maintenance procedures embedded directly in work orders address this directly. When a repair checklist — with photos, torque values, and safety steps — is built into the work order, a competent but unfamiliar technician can complete a complex repair significantly faster than they could working from memory or a paper manual kept in a filing cabinet two buildings away.
According to Reliabilityweb, facilities that embed standard operating procedures directly into their work orders report measurably higher first-time fix rates — meaning fewer repeat visits, fewer secondary failures, and lower MTTR per failure event. Guided procedures are particularly valuable during technician onboarding periods and any time contractors are performing critical repairs.
Well-maintained equipment fails in simpler ways. When a bearing is lubricated on schedule and inspected regularly, it fails gradually and predictably — typically as a single component replacement that takes 30 minutes. When the same bearing is neglected, it fails catastrophically, damaging the shaft, the housing, and sometimes adjacent components. The same asset type, but the MTTR is now 6 hours instead of 30 minutes.
Preventive maintenance directly reduces MTTR by limiting the scope of damage when failures do occur. It also reduces failure frequency, which means technicians are not permanently in reactive mode — they have time to prepare, plan, and stock the right parts before a job rather than scrambling in the middle of a production crisis.
A disciplined preventive maintenance software program, scheduled by calendar date or usage threshold, is one of the highest-leverage investments a maintenance team can make in MTTR reduction. The asset does not just fail less often — when it does fail, it fails in ways that are faster and cheaper to fix.
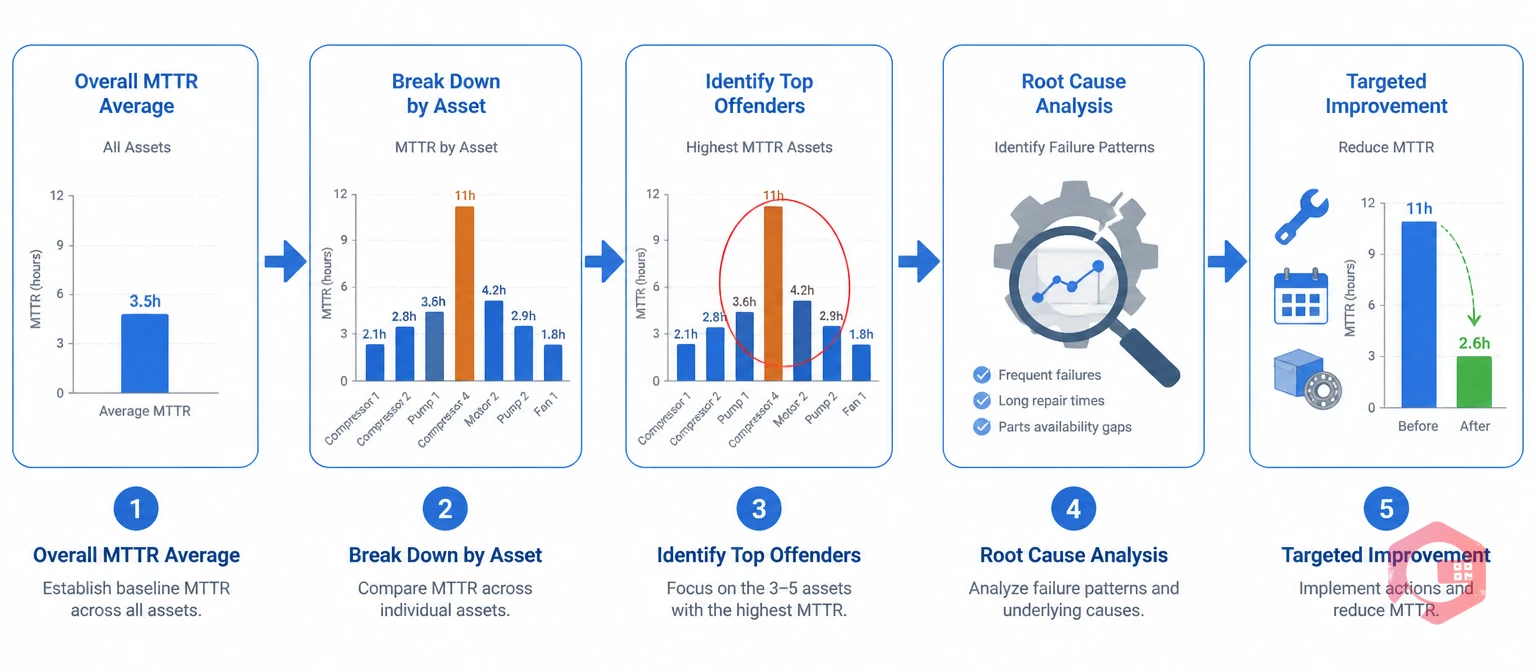
An overall MTTR of 3.5 hours sounds manageable until you discover that Compressor 4 has a consistent MTTR of 11 hours while everything else averages 2. The overall average masks the outlier, and the outlier is where the majority of your downtime loss is concentrated.
Asset-level MTTR tracking is essential for prioritizing where to invest improvement effort. When you can see which specific assets carry the highest MTTR and the highest failure frequency, you can focus root cause analysis where it will have the greatest operational impact. Commonly, 3 to 5 assets are responsible for 60 to 80% of total downtime hours — and those assets often share a common failure pattern that a targeted PM change or parts stocking adjustment would address.
Cryotos asset maintenance management tracks MTTR, MTBF, breakdown frequency, and repair cost at the individual asset level, and surfaces trends through a live BI dashboard. This is the data your team needs to stop applying generic solutions to specific problems — and to make a defensible case to leadership for where maintenance investment should go next.
Reducing MTTR requires improvements across every stage of the repair cycle: faster detection, faster dispatch, faster diagnosis, reliable parts access, and guided execution. Cryotos brings all of these levers into one platform, built for maintenance-intensive operations.
Teams using Cryotos report an average 25% reduction in repair time within the first six months of deployment. The platform delivers AI-powered work order creation via voice or photo, real-time asset history at the point of failure via QR scan, automated dispatch to the nearest available technician, and a live downtime dashboard that tracks MTTR by asset, department, and plant.
Beyond the core metrics, Cryotos connects your maintenance workflow to your spare parts inventory, your IoT sensor data, and your maintenance checklist library — closing the four gaps that drive most MTTR: slow detection, slow dispatch, incomplete diagnosis, and parts unavailability. Whether you are targeting a 20% MTTR reduction this quarter or building a long-term reliability program, the same platform serves both goals.
MTTR benchmarks vary significantly by industry and asset type. World-class maintenance operations typically target MTTR below 2 hours for standard equipment failures. For critical production assets, many leading facilities target sub-1-hour MTTR. The SMRP Best Practices guide recommends using your own historical baseline as the starting benchmark and measuring percentage improvement from there, rather than applying a universal target that may not reflect your asset mix.
MTTR measures how long repairs take after a failure. MTBF (Mean Time Between Failures) measures how often failures occur. Both metrics matter: reducing MTTR minimizes the impact of each failure, while improving MTBF reduces how frequently failures happen in the first place. World-class maintenance programs work on both simultaneously, using MTTR data to fix repair processes and MTBF data to improve asset reliability.
Yes, significantly. Preventive maintenance limits the scope of damage when failures occur, which directly reduces repair time. A bearing replaced during a scheduled PM takes 30 minutes; the same bearing left to fail catastrophically can cause secondary damage to connected components that takes 6–8 hours to repair. Consistent PM is one of the most reliable and cost-effective MTTR reduction levers available to any maintenance team.
Manually, MTTR = (Total repair hours in a period) ÷ (Number of repair events in that period). You can track this in a spreadsheet for small asset fleets. However, manual tracking becomes inaccurate as asset count grows, and it cannot provide the asset-level breakdown that reveals which specific equipment is driving your overall average up. A CMMS automates the calculation in real time and surfaces outliers automatically.
The four most common causes are: slow fault detection (a long gap between failure and alert reaching the team), slow dispatch (manual work order creation and technician notification processes), diagnostic delays (no asset history or repair procedure available at the point of failure), and parts unavailability (critical spares out of stock when needed most). Most facilities experience all four simultaneously, which compounds the total repair time well beyond what any single cause would produce alone.
Every hour your assets spend offline is revenue you cannot recover. Schedule a free demo to see how Cryotos cuts MTTR across your maintenance operation — from faster work order dispatch to real-time asset-level downtime tracking.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











