
Incident severity classification is the process of ranking workplace incidents by their potential consequences — injury impact, asset damage, production loss, environmental harm, and regulatory exposure — to determine how fast your organisation must respond and at what level. Without a structured classification system, every breakdown gets treated the same way: some critical events receive a slow response, and minor issues trigger unnecessary escalations. A four-level severity framework — Low, Medium, High, and Critical — gives maintenance, EHS, and operations teams a shared language that converts incident data into prioritised action. Organisations that pair this framework with a CMMS reduce average incident response time and cut repeat failures by systematically tracking root causes against severity levels.
Key Takeaways

Treat every incident the same and you guarantee two outcomes: critical events get delayed responses, and low-risk events consume resources they do not warrant. Severity classification solves both problems by building a triage layer between the incident report and the response workflow.
The business case is straightforward. A low-severity housekeeping issue and a high-severity chemical exposure cannot share the same notification path, the same investigation depth, or the same resolution deadline. The first warrants a corrective work order within a week. The second demands an immediate shutdown, a root cause investigation, a regulatory notification, and a corrective and preventive action plan before the affected area reopens.

The most common failure in incident management is not a lack of classification levels — it is the inconsistency of applying them. Two supervisors assessing the same incident often reach different severity ratings because they are weighing different factors. A configurable severity matrix standardises the decision by evaluating six specific dimensions simultaneously.
The most visible dimension. Classification should reflect the actual outcome as well as the credible worst-case outcome. A near-miss that could have caused a fatality under slightly different conditions warrants a higher severity rating than its actual outcome suggests. Criteria typically span from no injury through first aid, restricted duty, lost-time injury, permanent disability, and fatality.
Equipment failures vary enormously in their criticality. A damaged non-critical tool and a failed primary production asset both represent asset damage, but the response priority, investigation depth, and CAPA requirements differ significantly. The matrix should reference your asset tracking data — specifically criticality tier — to calibrate this dimension accurately.
Environmental severity spans from a contained minor spill to an uncontrolled release with off-site consequences. Regulatory thresholds under ISO 14001, OSHA, and regional environmental standards define reporting obligations that must be reflected in your matrix criteria. This dimension is particularly important for oil and gas, chemical, food and beverage, and pharmaceutical operations.
Express this dimension in hours of production loss and percentage of capacity affected. A one-hour delay on a non-critical line and a four-hour stoppage on a bottleneck asset carry fundamentally different business consequences. Connecting the severity matrix to your downtime tracking data ensures this dimension reflects actual operational risk rather than a generic scale.
Calculate total financial exposure across direct repair costs, production loss, regulatory fines, and reputational damage. Set monetary thresholds that align with your organisation's financial risk appetite and escalation authority levels. An incident that crosses a defined financial threshold should automatically escalate to management notification regardless of how the other dimensions score.
Certain incident types carry mandatory reporting obligations under ISO 45001, OSHA 29 CFR 1904, and industry-specific standards. The matrix must flag these obligations at the point of classification — not after an investigation — so that compliance teams receive early notification and reporting deadlines are not missed. This dimension requires regular review as regulatory requirements evolve.
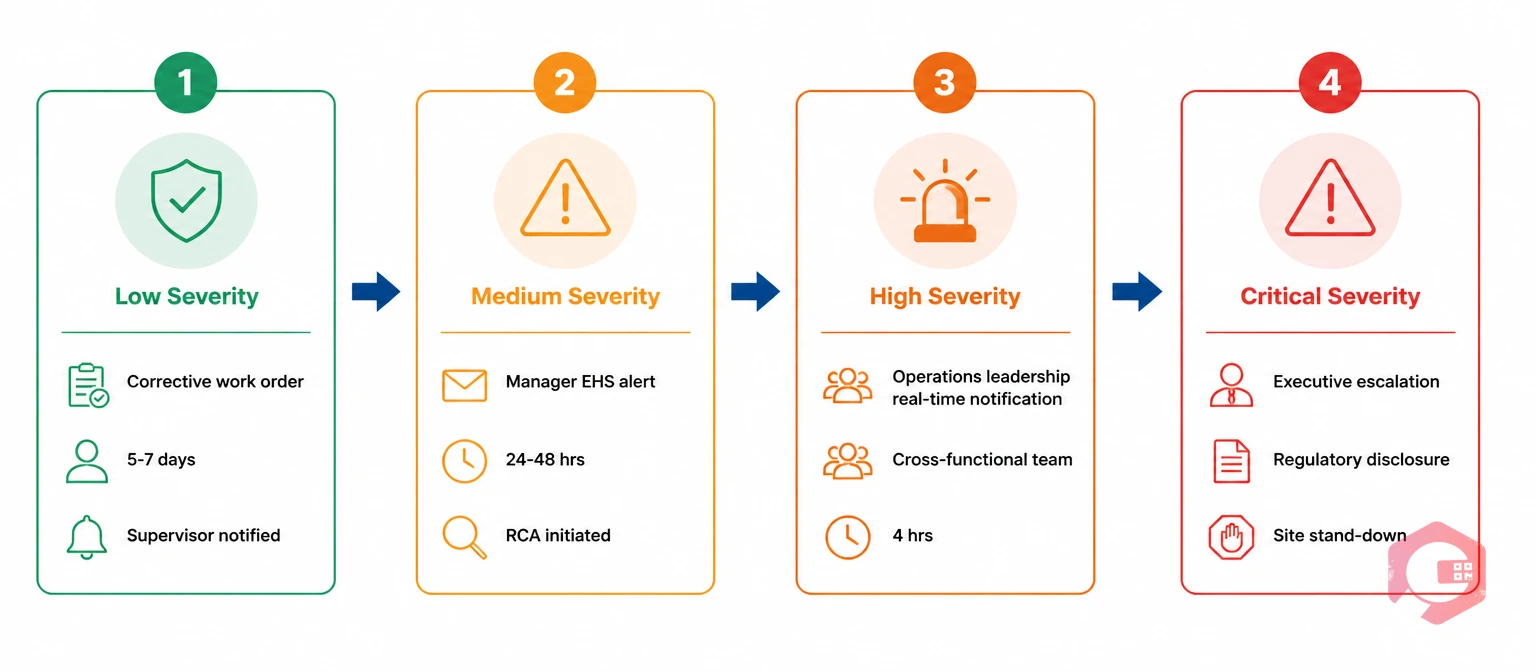
Classification has no operational value unless it automatically triggers the correct response. A severity level that sits in a log without generating notifications, assignments, and SLA targets is not a classification system — it is a record-keeping exercise.
Manual escalation consistently breaks down under the pressure of a real incident. The supervisor is managing the immediate response, the EHS coordinator is at a different site, and the regulatory clock is already running. Workflow automation removes this dependency: severity classification triggers notifications, assigns investigation tasks, sets deadlines, and generates the compliance documentation trail without requiring anyone to remember the protocol under pressure.
Severity classification defines the urgency. Role-based assignment defines who acts. These two mechanisms must work together — a critical incident assigned to the wrong team, or to a team without the authority to escalate, wastes the value of the classification entirely.
A well-structured role assignment matrix for incident management typically maps severity levels to the following stakeholder groups:
The user role and level access controls in your CMMS should enforce these assignment rules automatically, so that a Critical incident cannot be closed out at the maintenance supervisor level without senior approval.

Low-severity incidents warrant corrective action. Medium and High severity incidents warrant investigation. The distinction is important: corrective action fixes the immediate problem; investigation identifies the system failure that allowed the problem to occur.
The 5 Whys methodology embedded directly in the investigation work order means the investigation is not a separate administrative task — it is part of the incident closure workflow. A technician or EHS investigator cannot close a Medium or High severity incident without completing the required analysis fields.
A maintenance technician sustains a minor hand laceration while removing a faulty guard on a conveyor belt. The 5 Whys investigation surfaces the following:
The root cause is a process failure in template governance — not a technician error. The corrective action is a template audit across all asset classes, not a training reminder. Without structured RCA, that root cause is never reached. The root cause analysis investigation checklist ensures investigators follow a consistent method rather than stopping at the surface symptom.

Root cause analysis produces findings. CAPA converts findings into actions with owners, deadlines, and verification steps. The distinction matters: a finding that sits in an investigation report without a tracked corrective action has not reduced risk — it has documented it.
An effective CAPA framework for incident severity management operates on three rules:
An incident associated with an asset is a data point in that asset's reliability history. When incidents are logged without an asset reference, the connection between failure patterns and safety events is invisible. When incidents are associated directly with specific assets, recurring failure modes surface quickly and maintenance prioritisation adjusts accordingly.
Asset-centric incident management enables three analyses that generic incident tracking cannot support:
The quality of incident data degrades with every minute between the event and the report. A field technician reporting an incident from memory four hours later — because there was no accessible reporting tool on the floor — misses details, underestimates severity, and forgets contributing factors that an investigation team would need.
Mobile incident reporting with photo and video attachment addresses this degradation by making the report as fast and contextual as the event itself. A technician reports directly from the field: severity classification is prompted by the mobile form, photos of the affected area are attached at submission, and the automated workflow begins while the evidence is still intact. The mobile CMMS offline capability matters particularly in areas with limited connectivity — underground facilities, remote sites, confined spaces — where reports submitted offline sync automatically when connectivity is restored.
Incident classification and response workflows generate the data that management and EHS teams need to assess safety programme effectiveness. Without a dashboard that surfaces this data in real time, that assessment happens quarterly at best — after the pattern has already produced additional incidents.
A well-configured incident management dashboard should surface the following without manual data compilation:
The BI dashboard converts this data into a predictive risk view: if the frequency of Medium severity incidents on a specific production line is increasing month-over-month, the trend predicts a High severity event before it occurs. Acting on that trend — adjusting the PM schedule, reviewing operating procedures, inspecting related assets — is the operational definition of predictive risk management.
ISO 45001 and OSHA compliance require more than incident reporting — they require demonstrable evidence that classification, investigation, corrective action, and regulatory notification happened systematically and on time. A paper-based or spreadsheet-driven incident management process cannot reliably provide this evidence under audit conditions. Every step in the digital incident management workflow — classification, assignment, investigation initiation, CAPA creation, approval, and closure — carries a timestamp, a user attribution, and an immutable record. This means an auditor requesting evidence that a High severity incident received management notification within four hours can see exactly when the notification was sent, a regulatory inspector asking for CAPA completion evidence receives a formatted report rather than a file search, and an internal safety review comparing severity trends across sites pulls consistent data because classification criteria are standardised organisation-wide.
The safety compliance checklist embedded in each investigation work order creates the procedural evidence trail that demonstrates the organisation's safety management system is operating as designed, not just as documented.
Incident severity measures the magnitude of harm if an incident occurs — covering injury, asset damage, environmental impact, production loss, and regulatory exposure. Incident probability measures how likely the incident is to occur. A risk matrix evaluates both: a high-severity, low-probability event may warrant a different response priority than a medium-severity, high-probability event. Severity classification in incident management focuses on actual or potential consequence rather than probability, which is assessed separately during hazard identification and risk assessment.
Apply the precautionary principle: when severity is unclear, classify at the higher level until investigation confirms otherwise. A tentative Critical classification that is later downgraded to High after investigation is operationally preferable to a tentative Medium classification that proves to be High after the response window has passed. Most digital incident management systems allow severity to be updated during investigation with the original classification retained in the audit trail.
At minimum, the reporter should provide the type of event, the location and asset involved, the immediate injury or damage outcome, and an initial assessment of production impact. The severity matrix guides the classification from this information. Photo and video attachment from mobile reporting adds significant context that improves classification accuracy, particularly for asset damage and environmental impact dimensions.
Review severity matrix criteria at minimum annually and whenever a regulatory standard affecting your organisation is updated. Additional triggers include any Critical severity incident — post-investigation findings may reveal criteria that do not capture a failure mode the matrix should address — and any significant change in production processes, asset base, or workforce composition that alters the operational risk profile.
Incident severity classification transforms a workplace safety programme from a compliance obligation into an operational risk management system. When classification criteria are consistently applied, response workflows are automated against severity levels, root cause investigations are tied to corrective actions with verified close-out, and incident data feeds into predictive maintenance decisions, the gap between reporting an incident and preventing the next one closes measurably. Cryotos gives EHS, maintenance, and operations teams the tools to implement this framework in a single platform — from mobile field reporting and automated escalation to structured RCA, CAPA tracking, and real-time compliance dashboards. Schedule a free demo to see how incident severity classification works in practice.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











