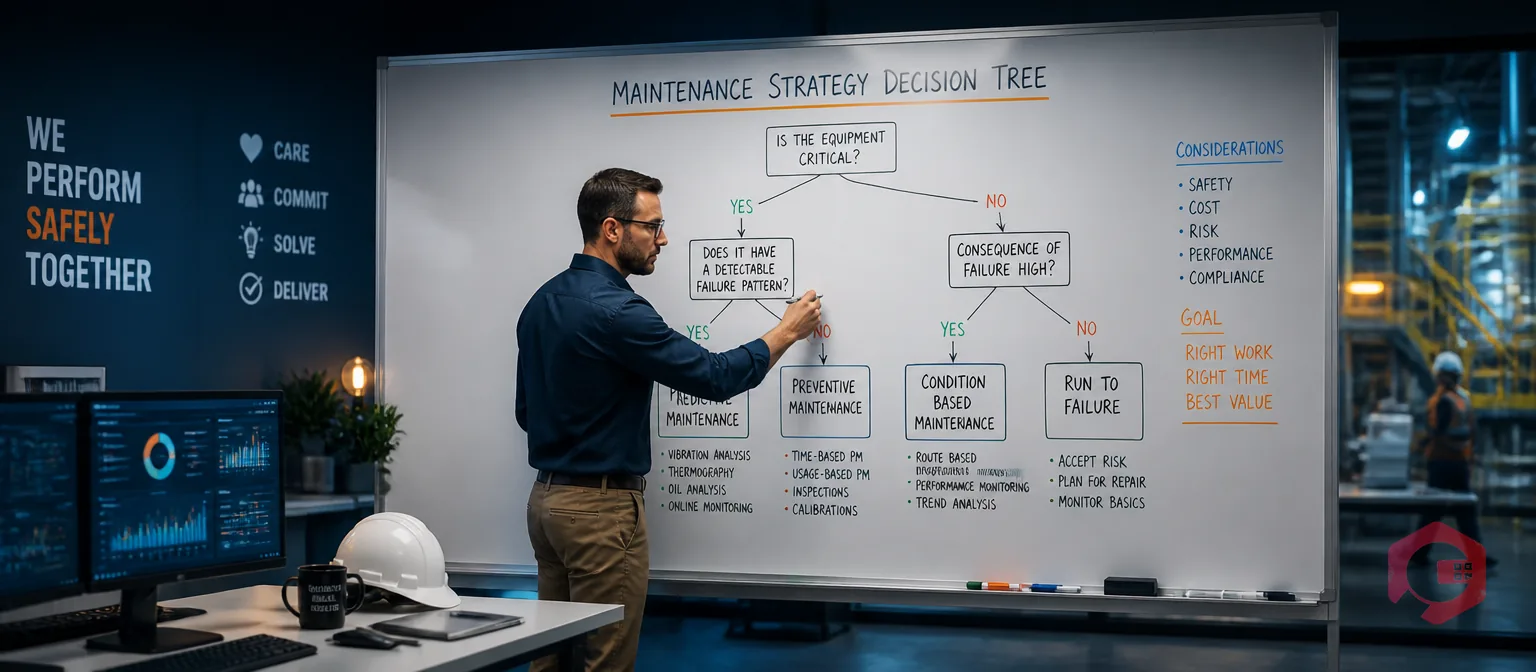
A maintenance decision tree is a branching flowchart that helps you pick the right maintenance strategy for each asset by answering a short series of yes/no questions about failure consequences, failure patterns, and cost. Instead of guessing whether a machine needs preventive, predictive, or run-to-failure maintenance, you follow the branches until you land on the strategy that fits that specific asset. It turns a fuzzy judgment call into a repeatable, defensible decision your whole team can follow.
The payoff is real: applying the wrong strategy is expensive in both directions. Over-maintain a low-risk asset and you waste labor and parts; under-maintain a critical one and you risk unplanned downtime that, according to research compiled by industry safety bodies, can carry serious safety and cost consequences. A decision tree keeps you out of both ditches.

A maintenance decision tree is a structured logic map. You start at the top with one asset, ask a question, and each answer routes you down a different branch until you reach a recommended strategy at the bottom. Think of it as the maintenance version of a doctor's triage: the symptoms (failure consequences, how the asset fails, how much intervention costs) determine the treatment.
The strength of the tool is consistency. When five planners each use their judgment, you get five different answers. When they all walk the same tree, you get one answer grounded in shared criteria. It also makes your reasoning auditable — if a regulator or plant manager asks why a pump is on run-to-failure, you can point to the exact branch you followed, with maintenance types defined consistently per ISO standards. Decision trees pair naturally with reliability-centered maintenance (RCM), which uses the same logic-driven approach to match tasks to failure modes.

Before you can build a tree, you need to know the destinations. Almost every decision tree routes assets toward one of these five strategies. Each one answers failure differently, and the right pick depends on what the asset does and how it fails.
You deliberately run the asset until it breaks, then repair or replace it. This is the right call — not laziness — when failure is cheap, has no safety impact, and the asset is easy to swap. Think light bulbs or non-critical hand tools. The key word is planned: a chosen run-to-failure approach is different from neglect.
You service the asset on a fixed schedule based on time or usage, regardless of condition. Preventive maintenance fits assets with predictable, age-related wear — belts, filters, lubrication points. It is simple to plan but can waste effort if you service equipment that was not yet due to fail.
You act only when a measured condition crosses a threshold — vibration, temperature, oil quality. Condition-based maintenance avoids unnecessary work but requires sensors or inspection routines to feed it real data.
You use condition data plus analytics to forecast when a failure will happen, then intervene just before it does. This is the most efficient strategy for critical assets, but it needs the most infrastructure — IoT sensors, historical data, and models. It is condition-based maintenance with a crystal ball.
RCM is not a single task type but a framework that analyzes each failure mode and assigns the most cost-effective strategy to it — which may itself be any of the four above. Formalized in standards such as SAE JA1011, it is the most thorough approach and the right destination for highly complex, high-consequence systems.
A good tree is built from a sequence of filtering questions, ordered so the highest-stakes factors come first. Walk an asset through these six questions in order, and the branches will steer you to a strategy.
Notice the order: safety and consequence come before cost. You never let a cheap repair bill override a safety risk. Linking your tree to an asset tracking system makes these questions easier to answer because the failure history is already there.
Once you understand the branches, this comparison helps you see at a glance which strategy fits which asset profile. Use it as a reference when you reach the end of a branch and want to confirm the fit.
| Strategy | Best For | Failure Consequence | Failure Pattern | Data Needed | Relative Cost |
|---|---|---|---|---|---|
| Run-to-Failure | Cheap, easily replaced assets | Low, no safety impact | Any | None | Lowest upfront |
| Preventive | Predictable, age-based wear | Medium | Predictable | Usage or time records | Moderate |
| Condition-Based | Assets with measurable warning signs | Medium to high | Random but detectable | Inspections or sensors | Moderate to high |
| Predictive | Critical assets with data history | High | Detectable, trendable | IoT sensors + analytics | High upfront, low long-term |
| RCM | Complex, high-consequence systems | Very high | Mixed failure modes | Full failure-mode analysis | Highest to implement |
Theory is easy; let's walk a real asset through the tree. Take a centrifugal pump feeding a production line in a food plant.
Start at question one: does failure threaten safety? No direct safety risk here, so we keep going. Question two: does failure stop production? Yes — this pump feeds the main line, so a failure halts output and risks a compliance issue with product holding times. That high consequence rules out run-to-failure immediately. Question three: is the failure pattern predictable? Pump bearings tend to fail randomly rather than purely with age, so a fixed time-based schedule alone would be inefficient. Question four: can we detect the failure developing? Yes — bearing wear shows up as vibration and temperature changes well before catastrophic failure. Question five: do we have sensors and data? The plant has vibration sensors and a year of readings. Question six confirms prevention is cheaper than a line stoppage.
The tree lands us on predictive maintenance: monitor vibration, trend it, and intervene just before the threshold. Had the plant lacked sensors, the same branch would have ended one stop earlier at condition-based inspections. Same asset, different answer based on capability — which is exactly why a tree beats a one-size-fits-all rule.
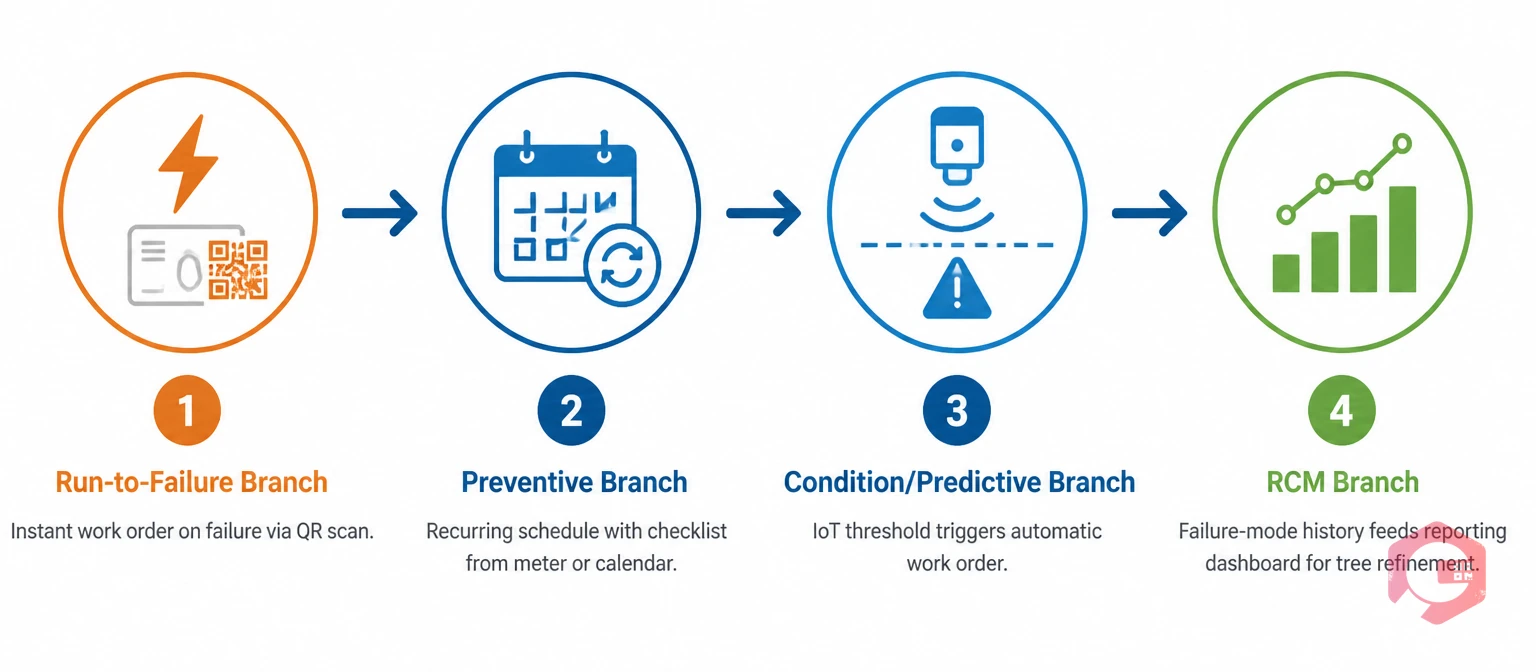
A decision tree gives you the right strategy, but a strategy on paper changes nothing. This is where a CMMS does the heavy lifting — it turns each branch into live, scheduled work.
Cryotos reports that customers using condition and downtime tracking see up to a 30% reduction in unplanned downtime and 25% faster repairs — gains that come from executing the right branch automatically rather than relying on memory. The CMMS also closes the loop: every completed work order feeds failure data back, so next year's tree is smarter than this year's.
A decision tree is only as good as how you use it. These are the errors that quietly undermine an otherwise solid framework.
It is used to select the most appropriate maintenance strategy for each asset by working through a series of questions about failure consequences, failure patterns, and cost. The goal is a consistent, defensible decision rather than relying on individual judgment that varies from planner to planner.
Choose preventive maintenance when failures follow a predictable, age-based pattern and you lack condition-monitoring data. Choose predictive maintenance when the asset is critical, failures are detectable through measurable signs, and you have the sensors and history to forecast them. The decision tree question about data availability is usually what separates the two.
Yes. Run-to-failure is the correct, deliberate choice for low-cost, easily replaced assets with no safety or production impact — such as light bulbs or non-critical tools. It only becomes a problem when it happens by neglect rather than by decision.
Review it whenever your failure history shifts meaningfully, when you add condition-monitoring capability, or at least annually. Aging assets change their failure patterns, so a tree that fit a new machine may route an old one onto the wrong branch over time.
You can design a tree on paper, but a CMMS is what makes it operational at scale. It turns each chosen branch into scheduled work orders, connects condition-based branches to sensor data, and feeds completed-work history back so you can refine the tree with real evidence.
A maintenance decision tree only delivers value when its branches translate into real, tracked work — and that is exactly what Cryotos CMMS is built to do. From run-to-failure work requests to sensor-driven predictive triggers, Cryotos executes whichever strategy your tree selects and feeds the results back so your decisions keep getting sharper. Book a demo to see how Cryotos can turn your maintenance strategy into action.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











