
Run to failure maintenance (RTF) is a deliberate strategy where equipment is allowed to operate until it breaks down before any repair is made. Unlike preventive maintenance, which services assets on a schedule, RTF reserves maintenance resources for the moment a failure actually occurs. It’s not negligence — when applied correctly, it’s a cost-effective decision that saves labor and materials on assets where failure carries minimal operational, safety, or financial risk.
RTF makes sense for roughly 20% of assets in a typical industrial environment. The remaining 80% — especially anything safety-critical, high-value, or production-critical — should never run to failure. Understanding which category each asset falls into is the foundation of a sound reliability-centered maintenance strategy.
Run to failure maintenance — sometimes called breakdown maintenance or reactive maintenance — is the intentional decision to perform no scheduled maintenance on an asset until it stops working. The work order is only created after a failure occurs.
The key word here is intentional. RTF as a strategy is fundamentally different from unplanned maintenance, which happens when a team lacks the systems to prevent failures on critical equipment. When RTF is a conscious choice — applied to the right assets, with spare parts on the shelf and technicians ready to respond — it’s an efficient use of maintenance budgets.
According to research cited by Plant Engineering, reactive maintenance can cost 3 to 5 times more per repair event than planned maintenance. That cost differential only applies when RTF is used on the wrong assets. For low-cost, non-critical items, the math tips the other way: maintaining an asset that costs $40 to replace on a $150-per-hour technician schedule is simply wasteful.
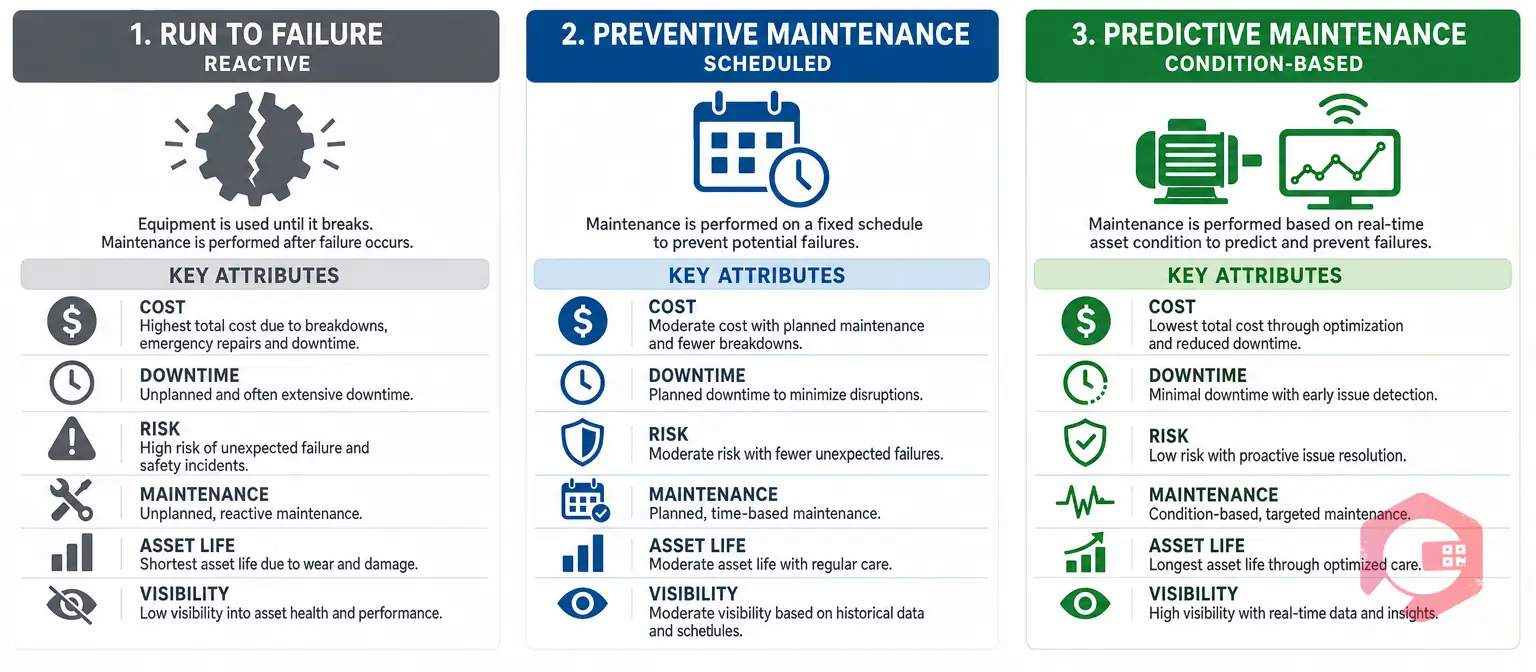
Before deciding when RTF is appropriate, it helps to see where it sits relative to other strategies:
Most mature maintenance programs blend all three. A 2022 analysis by Deloitte found that organizations with optimized maintenance strategies — applying the right approach to each asset class — reduce overall maintenance costs by 25 to 30% compared to those using a single blanket strategy. The question is never “which strategy is best?” but “which strategy is best for this specific asset?”

RTF is appropriate when an asset meets all — or nearly all — of the following criteria.
If the asset is inexpensive to replace and its failure has no downstream impact on production, safety, or quality, RTF is almost always the right choice. Office lighting, breakroom appliances, non-essential conveyors on parallel lines, and low-cost pneumatic tools are typical candidates. Tracking mean time between failures on a $30 component with a 15-minute replacement time is rarely worth the administrative overhead.
If an asset has a fully operational backup that automatically takes over on failure — such as a redundant pump, a backup generator that is tested regularly, or a secondary cooling circuit — allowing the primary asset to run to failure adds no operational risk. The key requirement is that redundancy must be real and tested, not theoretical. An untested backup isn’t redundancy; it’s a second failure waiting to happen.
This condition is non-negotiable. If equipment failure could injure workers, release hazardous materials, or create an unsafe condition, RTF is categorically the wrong strategy. OSHA’s control of hazardous energy standard (29 CFR 1910.147) mandates documented maintenance procedures for energy-isolating devices — waiting for these assets to fail before acting is a compliance violation, not just a strategic error.
Run the numbers. If preventive maintenance on an asset costs $200 in labor per year, and the asset fails every three years with a $50 replacement cost plus 30 minutes of technician time, the math favors RTF. But if failure causes even one hour of production loss at $10,000 per hour, the calculation reverses immediately. This exercise is the single most useful filter for RTF decisions.
RTF works best when assets fail suddenly and completely — a fuse blows, a bulb burns out, a switch stops working — rather than progressively degrading. Progressive failures, such as bearing wear in rotating equipment, provide a P-F interval (the window between detectable potential failure and functional failure) that maintenance teams should exploit through condition monitoring, not ignore until breakdown.

RTF is misapplied far more often than it’s correctly used. These three categories should never run to failure.
Pressure vessels, electrical panels, fire suppression systems, lifting equipment, and any asset whose failure mode includes a risk of injury must be maintained proactively. A fire suppression system that fails because no one tested it isn’t a cost-saving decision — it’s a liability. Reliable Plant’s research on reliability programs consistently shows that safety incidents caused by deferred maintenance cost 10 to 50 times more in total than the maintenance they replaced.
A critical compressor with a six-week lead time on replacement parts is the wrong candidate for RTF. When the asset fails, you won’t simply replace it in 30 minutes. You’ll wait six weeks, losing production the entire time. These assets deserve asset maintenance management that tracks their condition, anticipates deterioration, and plans interventions before failure — not after it.
A failed $50 seal that contaminates a $40,000 gearbox isn’t a $50 failure — it’s a $40,050 failure. Any asset where the failure mode can cause secondary damage to larger, more expensive components should be maintained proactively. Monitoring downtime patterns across your asset fleet helps identify which failures consistently trigger these cascades.

Use this checklist to assess any asset for RTF eligibility. If the asset scores “No” on any single red-flag question, it should not run to failure regardless of how it scores on the others.
Assets that pass all disqualifiers and score favorably on cost, redundancy, and lead time are strong RTF candidates. Tracking failure frequency on these assets using your MTBF calculator will also tell you whether actual failure rates match your assumptions — and whether the RTF decision still makes financial sense over time.
Running an asset to failure isn’t the same as ignoring it. The most effective RTF programs are deliberate: the asset is classified, spare parts are stocked, and the response workflow is documented so that when failure occurs, the repair happens in minutes rather than hours.
Cryotos CMMS gives maintenance teams the infrastructure to manage RTF assets without letting them become a source of unplanned chaos. Here’s how:
The goal isn’t simply to tolerate failure on certain assets — it’s to respond to that failure so efficiently that the operational impact is negligible. A well-configured CMMS is what makes that possible.
The main risk is applying RTF to the wrong assets. When RTF is used on safety-critical or high-value equipment, a single failure can cost exponentially more in emergency repair, secondary damage, and production loss than a full year of preventive maintenance would have. The risk isn’t the strategy itself — it’s the classification error that leads to it being applied where it shouldn’t be.
Yes. For genuinely non-critical, low-cost, easily replaced assets, RTF removes unnecessary maintenance labor and parts usage. It also reduces the risk of “infant mortality” — the failure that sometimes occurs when a healthy machine is unnecessarily disassembled and reassembled during a preventive maintenance visit. RTF is a legitimate and cost-effective strategy when applied to the right asset class.
Start with a criticality analysis. Any asset whose failure creates safety risk, production loss, regulatory exposure, or cascading damage to adjacent equipment should be excluded from RTF. What remains — low-cost, non-critical assets with available spares — are your RTF candidates. Use the five-condition framework above to confirm, and track failure data over time to validate that the classification still makes financial sense.
Industry practice typically places RTF assets at around 15 to 20% of total asset inventory by count. By maintenance cost, the figure is far lower — because the assets eligible for RTF are, by definition, low-cost. A 2023 survey by the Maintenance World community found that high-performing maintenance organizations dedicate 70 to 80% of planned maintenance effort to their top 20% most critical assets, with the remainder managed reactively.
Absolutely. A CMMS like Cryotos lets maintenance teams classify assets by criticality, pre-stock spare parts for RTF assets, and respond to failures with speed and accuracy using mobile work orders. The CMMS also tracks failure history, so teams can identify RTF assets that are failing more often than expected and re-evaluate their classification before that pattern becomes a budget problem.
Run to failure is a powerful maintenance strategy when applied precisely — but misapplication is expensive and dangerous. The discipline is in the classification work upfront: understanding which assets are truly eligible, stocking parts before failure occurs, and building a response process that makes the inevitable breakdown a non-event. Cryotos CMMS gives maintenance teams the asset classification, inventory management, and rapid work order tools to make strategic RTF work in practice — not just in theory.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











