
Value-driven maintenance is a strategic approach that evaluates every maintenance task — planned or reactive — against the specific business outcome it protects or produces. Rather than treating maintenance as a cost to minimise or a schedule to comply with, value-driven maintenance frames each task as an investment with a measurable return: revenue protection, asset life extension, safety cost avoidance, or regulatory compliance. According to McKinsey’s research on industrial maintenance, companies that apply value-linked maintenance frameworks reduce overall maintenance costs by 10–25% while improving asset availability by 20–30% — because they stop spending on low-value tasks and concentrate effort where business impact is highest.
Key Takeaways

Value-driven maintenance is the discipline of connecting every maintenance decision — which assets to prioritise, which tasks to schedule, how often to inspect, when to replace — to a clearly articulated business outcome. It asks a single question before any maintenance investment is made: what value does this task protect or produce for the business?
The concept sits at the intersection of reliability engineering and operational finance. A maintenance team operating on a value-driven model does not schedule tasks because the calendar says so or because the OEM recommends it as a default. They schedule tasks because the failure data, asset criticality, and downtime cost analysis confirm that the task delivers a return that exceeds its cost. Tasks that fail that test are redesigned, de-scoped, or eliminated.
Value in this context takes four specific forms. The first is revenue protection — keeping production assets running so that output targets are met. The second is asset life extension — reducing wear and degradation so that capital replacement is deferred. The third is safety and compliance cost avoidance — preventing incidents, regulatory penalties, and the indirect costs that follow. The fourth is operational efficiency — reducing the labour, parts, and overhead consumed by unplanned failure response.
Value-driven maintenance is not a rejection of preventive maintenance or reliability-centred maintenance frameworks. It is the business logic layer that sits above those frameworks — the discipline that ensures the right maintenance strategy is applied to each asset based on the value at stake, not on habit, conservatism, or blanket schedules. A CMMS (Computerized Maintenance Management System) is the data infrastructure that makes this discipline operational at scale, capturing the failure history, cost records, and performance metrics that value decisions depend on.
The contrast between reactive and value-driven maintenance is not simply planned versus unplanned. It is the difference between a cost-centre mindset and an investment mindset — and the operational outcomes that result from each.
| Dimension | Reactive Maintenance | Value-Driven Maintenance |
|---|---|---|
| Decision trigger | Equipment failure or visible degradation | Business risk analysis and asset criticality |
| Task priority | Urgency of the breakdown | Business value at stake if the asset fails |
| Budget view | Maintenance as a cost to contain | Maintenance as an investment with measurable ROI |
| Performance metric | Work orders completed, response time | Asset availability, downtime cost, maintenance-to-revenue ratio |
| Leadership conversation | "We fixed it; here is what it cost" | "This PM prevented $X in downtime; here is the ROI" |
| PM schedule basis | OEM default or fixed calendar | Failure data, asset criticality, and cost-benefit analysis |
| Outcome | Variable costs, unpredictable downtime | Predictable spend, measurable uptime improvement |
The shift from reactive to value-driven is not achieved by adding more preventive maintenance tasks. Over-maintenance is as much a value problem as under-maintenance — it consumes technician hours and parts budget on tasks that return little business value. According to SMRP maintenance best practice guidance, world-class maintenance organisations direct more than 80% of their maintenance effort toward planned, value-assessed work — and continuously review that effort to ensure the tasks being done are the tasks that matter most.
The practical difference shows up most clearly in how the two approaches handle asset criticality. A reactive team treats every breakdown as equally urgent and every PM as equally necessary. A value-driven team has a clear tiered model: Tier 1 assets whose failure directly stops revenue get the highest maintenance investment; Tier 3 assets whose failure has minimal operational impact get a run-to-failure or low-frequency inspection approach. The same total budget delivers far better business outcomes when it is concentrated on the assets where failure cost is highest.
Every maintenance task, when evaluated honestly, produces value in one or more of four categories. Understanding these categories is the foundation of a value-driven maintenance framework — because it gives maintenance managers the language to explain, justify, and prioritise every activity in terms that operations, finance, and executive leadership can directly act on.
The first value category is revenue protection. On any production line, packaging operation, or processing facility, the direct relationship between asset uptime and output is quantifiable. A conveyor that runs 250 production days per year and produces $8,000 of output per operating hour represents $2 million in annual revenue risk if it reaches zero uptime. Every PM task performed on that conveyor is not a cost — it is the protection of a specific fraction of that $2 million. Downtime tracking in a CMMS makes this value explicit: actual downtime duration multiplied by revenue-per-hour gives a concrete number that justifies every planned maintenance dollar spent to prevent it.
The second value category is asset life extension. Capital equipment has a finite service life, and deferred replacement is a direct financial benefit. A centrifugal pump with a standard replacement cycle of 12 years that reaches 16 years in service through proper lubrication, alignment maintenance, and seal management has delivered four years of capital deferral. At a replacement cost of $45,000, that is $45,000 preserved in the capital budget — value that no accountant will dispute once it is framed that way. Maintenance management software that tracks total maintenance cost per asset makes the capital-deferral case visible across the full asset portfolio.
The third value category is safety and compliance cost avoidance. A failure that causes a workplace injury triggers workers’ compensation claims, regulatory investigations, production stoppages, and reputational damage — costs that dwarf the maintenance investment that would have prevented the failure. A facility with a strong unplanned maintenance rate is also a facility with a higher probability of safety incidents, because uncontrolled failures are the most common precursor to unsafe conditions. Every planned maintenance task on a safety-critical asset carries a compliance value that should be calculated and reported alongside its operational value.
The fourth value category is operational efficiency. Reactive maintenance consistently costs 3–5 times more than planned maintenance for the same repair scope — because it involves emergency parts procurement at premium prices, overtime labour, collateral damage from running a degraded asset, and production disruption that spreads beyond the immediate repair window. According to Plant Engineering’s maintenance benchmarking research, facilities that achieve a planned-to-reactive maintenance ratio of 4:1 or better spend significantly less per maintained asset than those operating reactively — even when the labour and parts costs of planned work are fully accounted for. Every planned task that prevents a reactive event captures the cost differential as operational efficiency value.
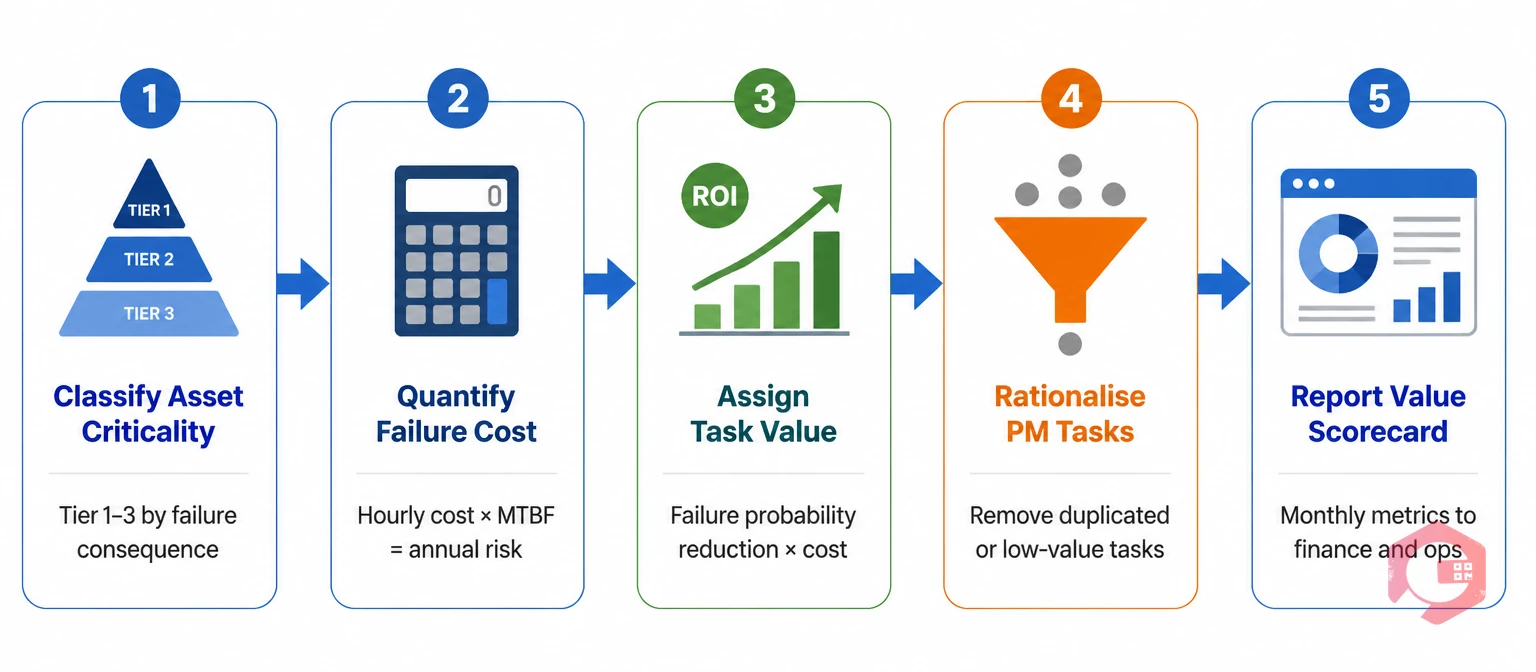
Linking tasks to business value requires a structured process that moves from asset inventory through criticality assessment to task-level value assignment. This is not a one-time exercise — it is an ongoing discipline that improves as failure data accumulates in your CMMS.
The process starts with asset criticality classification. Every asset in your facility is assigned to one of three tiers based on the consequence of failure: Tier 1 (failure stops production, creates safety risk, or triggers regulatory consequence), Tier 2 (failure degrades output or creates operational inconvenience but has a workaround), and Tier 3 (failure has minimal operational impact and is easily recoverable). This classification drives the maintenance investment level for each asset — Tier 1 assets warrant the highest maintenance frequency and the most sophisticated monitoring; Tier 3 assets may be managed with run-to-failure or minimal inspection.
With criticality classified, the next step is failure consequence quantification for Tier 1 and Tier 2 assets. For each asset, calculate the hourly cost of failure across all consequence dimensions: lost production, emergency labour premium, unplanned parts procurement, and any safety or compliance exposure. Multiply by the mean time between failures (MTBF) to get an annualised failure cost. This number becomes the value ceiling — the maximum justified investment in maintenance tasks for that asset per year.
Task-level value assignment follows from consequence quantification. For each planned maintenance task on a Tier 1 or Tier 2 asset, estimate the reduction in failure probability that the task delivers. A lubrication task that reduces bearing failure probability by 60% on an asset with an annualised failure cost of $120,000 delivers an expected value of $72,000 per year. If the task costs $800 to perform, the ROI is over 89:1 — and no finance leader can argue against that number.
Tasks that cannot be linked to a quantifiable value outcome fall into one of two categories: tasks that protect a value that has not been calculated yet (in which case the analysis is incomplete, not the task) or tasks that have outlived their purpose and should be eliminated. A value-driven maintenance audit of a typical industrial facility routinely surfaces 15–25% of PM tasks that are either duplicated, over-frequent, or no longer aligned with the current asset configuration — representing budget and labour that can be reallocated to higher-value activities. Use your preventive maintenance software to review PM compliance data, task completion times, and finding rates to identify candidates for rationalisation.
The final step is building a value reporting cadence. Monthly or quarterly, maintenance managers should present a value scorecard to operations and finance leadership that shows: total planned maintenance spend, downtime prevented (converted to revenue value), PM compliance rate, and MTBF trend for Tier 1 assets. This scorecard transforms maintenance from a cost line to a business function with a visible, defensible return — and it makes the case for maintenance investment in terms that decision-makers understand and act on.

The weakest link in most maintenance value arguments is the measurement layer. Teams that cannot produce concrete numbers when leadership asks what maintenance delivered this quarter will always be vulnerable to budget cuts — regardless of how much value they are actually creating. These six metrics form the core of a value-driven maintenance dashboard.
Asset availability percentage is the most direct measure of maintenance value in production environments. It tells leadership what fraction of scheduled production time assets were actually available to run. A 2% improvement in asset availability on a critical production line running 6,000 hours per year at $5,000 of output per hour represents $600,000 in protected revenue. This single metric, trended over time, demonstrates maintenance value more clearly than any cost reduction argument.
Planned maintenance percentage (PMP) measures the proportion of total maintenance hours spent on planned versus reactive work. A rising PMP indicates that the maintenance team is gaining control of failure patterns and shifting budget from expensive reactive repair to efficient planned maintenance. World-class facilities target PMP above 80%. Below 60% signals that reactive demand is overwhelming the planned programme and that the value-driven framework has not yet taken hold.
Maintenance cost as a percentage of asset replacement value (MCAV) provides a normalised view of maintenance spend that is comparable across sites, asset classes, and industry benchmarks. Best-in-class manufacturing facilities typically run MCAV between 1.5% and 3%. Facilities above 5% are usually trapped in a high-reactive cycle; facilities reporting below 1% are often under-maintaining and accumulating deferred failure risk that will surface as capital replacement or major incident cost.
Mean Time Between Failures (MTBF) by asset and asset class tells you whether maintenance interventions are actually extending the reliable operating life of equipment. A rising MTBF on Tier 1 assets after PM schedule changes is concrete evidence that the planned maintenance programme is working. A flat or falling MTBF despite consistent PM compliance is a signal that the current task set is not addressing the actual failure mode — and that a design-out or strategy review is needed.
Downtime cost prevented converts asset availability data into a financial number. For each planned maintenance event that successfully prevented a known failure mode, calculate the downtime cost that would have been incurred if the failure had occurred instead. Aggregated across all Tier 1 and Tier 2 assets over a quarter, this figure is the most powerful value argument available — it shows leadership not what maintenance cost, but what it saved.
PM compliance rate measures the percentage of scheduled preventive maintenance tasks completed on time. It is a process health metric rather than an outcome metric, but it is foundational: value-driven maintenance only works if the planned tasks are actually executed. A PM compliance rate below 85% signals scheduling overload, parts shortages, or skill coverage gaps that are putting planned value at risk.
Value-driven maintenance is not achievable without a structured data foundation. Every step of the value-linking process — criticality classification, consequence quantification, task ROI calculation, and outcome verification — depends on failure history, work order cost records, and real-time performance metrics that only a CMMS captures consistently and at scale.
The most immediate contribution of a CMMS is making failure patterns visible. When every work order is closed with a failure code, root cause, parts cost, and labour time captured against a specific asset ID, the CMMS builds a failure history that surfaces which assets are consuming disproportionate maintenance resources, which failure modes are recurring, and where the highest value maintenance investments are justified. Without this history, value-driven decisions are guesswork — managers make assumptions about asset criticality and task importance that are often wrong, and no one can prove it either way.
Cryotos’s work order management software captures all of this data as a natural byproduct of technicians closing jobs on mobile — no separate data entry, no end-of-shift paperwork, no reliance on individual memory. Each closed work order becomes a data point in the failure history that drives every subsequent value decision.
The second contribution is PM schedule optimisation. Cryotos supports both calendar-based and usage-based PM triggers, meaning tasks fire based on what the asset has actually done rather than on a fixed calendar that ignores real operating conditions. When a compressor runs continuously through a high-demand season and at 40% load through winter, its PM interval should reflect actual wear accumulation — not an arbitrary date. This dynamic scheduling is the operational expression of value-driven maintenance: maintenance resources are concentrated in periods and conditions where the risk of failure is highest and the value of prevention is greatest.
The third contribution is the visibility layer for leadership. Cryotos’s BI Dashboard surfaces asset availability, MTBF trends, downtime by cause, and maintenance cost per asset in real time — the exact metrics that constitute a value-driven maintenance scorecard. When a maintenance manager walks into a budget review with a live dashboard showing 94% asset availability on Tier 1 equipment, a rising MTBF trend across the critical asset fleet, and a quantified downtime-prevented figure for the quarter, the value conversation changes completely. Maintenance is no longer asking to justify its cost — it is presenting its return.
The fourth contribution is integration with the broader business. For organisations running SAP or Microsoft Dynamics 365, Cryotos’s ERP integration ensures that maintenance cost data flows directly into financial reporting, making the maintenance-to-revenue relationship visible to finance without manual reconciliation. IoT sensor integration via IoT meter reading means that condition data from critical assets feeds maintenance decisions in real time — triggering work orders before failure thresholds are crossed and capturing the condition-based value that calendar-only PM schedules miss.
According to Reliable Plant’s CMMS benchmarking research, organisations with CMMS-supported maintenance programmes consistently outperform those without on every value metric: lower MCAV, higher asset availability, better PM compliance rates, and lower emergency repair ratios. The CMMS is not the strategy — but it is the infrastructure that makes the strategy measurable, improvable, and defensible.
Value-driven maintenance is a strategic framework that evaluates every maintenance task against the specific business outcome it protects or produces. It classifies assets by criticality, quantifies the cost consequences of failure, and uses that data to concentrate maintenance investment where the return is highest — protecting revenue, extending asset life, avoiding safety and compliance costs, and improving operational efficiency. It is the business logic layer that sits above preventive or reliability-centred maintenance methodologies.
Preventive maintenance is a task execution strategy — scheduling regular servicing to prevent failures. Value-driven maintenance is the decision framework that determines which preventive tasks to schedule, at what frequency, on which assets, based on the business value at stake. A value-driven approach may include preventive maintenance, condition-based monitoring, and design-out strategies — selecting the right method for each asset based on criticality and failure cost rather than applying a single strategy uniformly.
Maintenance task ROI is calculated by dividing the value of the failure prevented by the cost of the task. The value of the failure prevented equals the estimated failure probability reduction (expressed as a percentage) multiplied by the full consequence cost of that failure — including production loss, emergency labour, parts premium, and any safety or compliance exposure. If a lubrication task reduces bearing failure probability by 60% on an asset with a $50,000 annual failure cost, it delivers $30,000 of expected value. If the task costs $500, the ROI is 59:1.
The six most effective metrics are: asset availability percentage (direct measure of uptime protected), planned maintenance percentage (ratio of planned to reactive work), maintenance cost as a percentage of asset replacement value (normalised spend benchmark), MTBF trend by asset class (evidence that PM is extending reliable operating life), downtime cost prevented (failure cost avoided through planned maintenance), and PM compliance rate (process health indicator that confirms planned value is being executed). Together, these metrics translate maintenance performance into the financial language that operations, finance, and executive leadership can directly act on.
A CMMS supports value-driven maintenance by capturing the failure history and work order cost data that asset criticality and task ROI calculations depend on, by optimising PM schedules based on actual usage data rather than fixed calendars, and by surfacing value metrics — availability, MTBF, downtime cost, maintenance spend per asset — on real-time dashboards that maintenance managers can present directly to leadership. Without CMMS data, value-driven maintenance decisions are based on assumptions rather than evidence, and the business case for maintenance investment is always weak.
If your maintenance team is doing good work but struggling to prove its value to the business, the gap is usually in the measurement layer — not in the execution. Cryotos gives maintenance managers the failure history, cost tracking, PM scheduling tools, and BI dashboards needed to link every task to a business outcome and present that outcome to leadership with confidence. Schedule a free demo and see how leading maintenance teams use Cryotos to transform maintenance from a cost centre into a measurable business asset.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











