
Operators are your first line of defense against unplanned downtime. They run machines for 8 to 12 hours a day — and they're the first to notice when something changes. A sound that's slightly off. A vibration that wasn't there last week. An oil patch on the floor that appeared overnight. When operators are trained to act on what they observe and equipped with tools to report it fast, failures that would have caused hours of lost production get caught in minutes.
According to a McKinsey study on maintenance transformation, companies that engage frontline operators in reliability programs reduce unplanned downtime by 25–35% compared to organizations that rely solely on dedicated maintenance teams. This blog explains how to build that first-line-of-defense system — from defining operator roles to implementing a digital reporting loop that ensures nothing falls through the cracks.
Operators run machines for 8 to 12 hours a day. They hear the hum change, feel the vibration shift, and notice the oil patch that wasn't there yesterday. Technicians are skilled — but they're often three steps removed from that moment when something first starts going wrong.
That gap is where unplanned downtime lives.
The "first line of defense" concept recognizes a simple truth: the person closest to the equipment is best positioned to catch problems early. When operators are trained, equipped, and encouraged to act on what they observe, failures that would have caused hours of lost production get caught in minutes.
According to a McKinsey study on maintenance transformation, companies that engage frontline operators in reliability programs reduce unplanned downtime by 25–35% compared to organizations that rely solely on dedicated maintenance teams.
When an operator notices an unusual sound but has no formal way to report it — or no expectation that reporting is their job — that issue sits unaddressed. By the time a technician discovers it during a scheduled inspection, what started as a loose bearing may have become a seized shaft. What would have been a 30-minute fix turns into a 6-hour replacement job, plus parts costs, plus lost output.
The cost of unplanned downtime runs high across every industry. In manufacturing, the average unplanned outage costs $260,000 per hour, according to Plant Engineering. Most of those events had early warning signs that went unreported.
IoT sensors are valuable. They track temperature, pressure, and vibration — but they're calibrated to detect known failure modes. Operators pick up on subtler signals: a conveyor belt that sounds slightly different under load, a pump that now requires more manual force to start, a machine that vibrates in a way it didn't last Tuesday.
Human perception, applied with purpose, is a detection layer that no sensor array fully replicates. The goal isn't to replace technology — it's to make sure your operators are an active part of the reliability system, not passive bystanders waiting for breakdowns.
Confusion about roles is one of the biggest barriers to operator-led maintenance. When operators think "that's not my job," and technicians assume operators aren't trained to help, neither party acts. Here's how responsibilities should be divided:
| Responsibility | Operator | Technician |
|---|---|---|
| Daily visual inspection | Owns it | Reviews findings |
| Lubricating equipment | Basic lubrication | Complex lube systems |
| Reporting abnormalities | First reporter | Diagnoses and acts |
| Minor tightening/adjustments | Within safe scope | Anything requiring disassembly |
| Housekeeping around equipment | Daily | Deep clean during shutdown |
| Scheduled preventive maintenance | Assists when trained | Owns it |
| Root cause analysis | Provides context and evidence | Leads investigation |
| Parts replacement | Simple consumables only | Owns it |
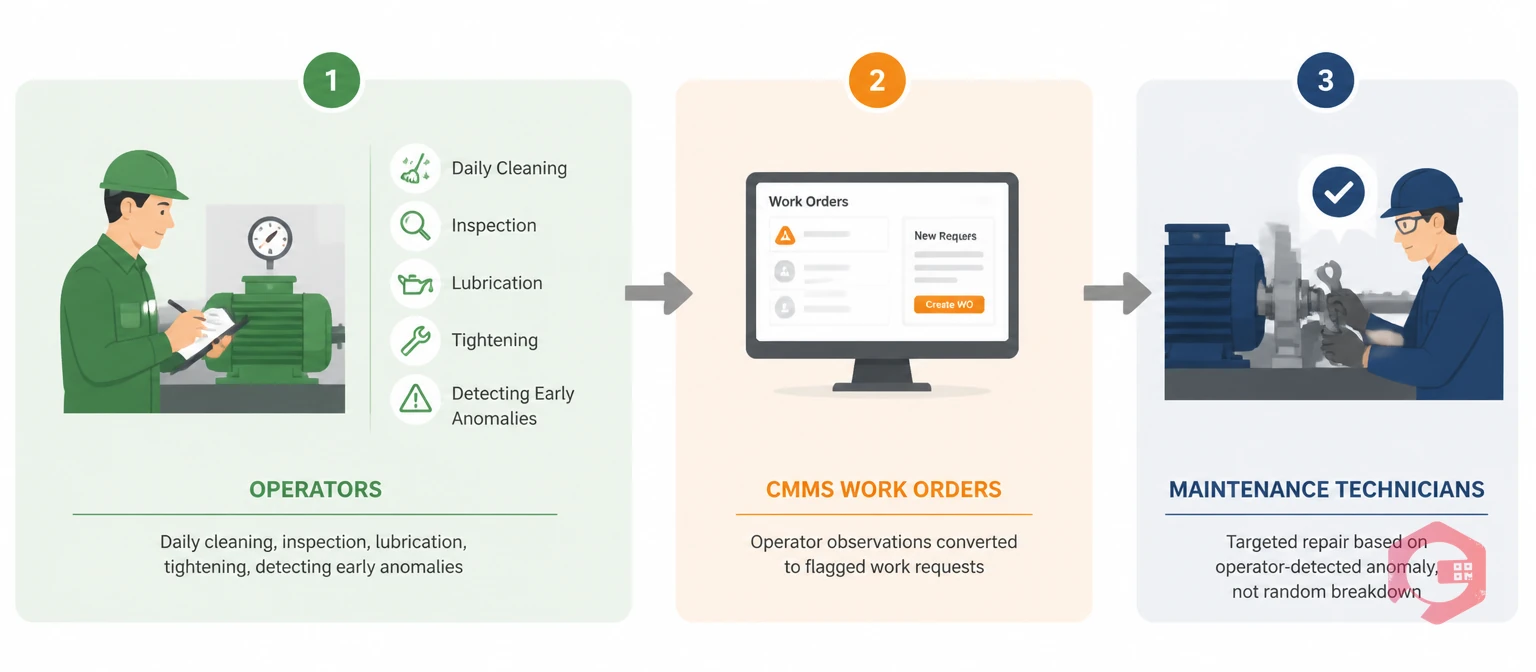
The dividing line is safe scope and skill level. Operators handle observation, reporting, basic servicing, and cleanliness. Technicians handle diagnosis, repair, and complex maintenance tasks. Neither role replaces the other — they form a two-tier system where operators catch and report, technicians investigate and fix.

You don't need a complete program to start. These five activities, done consistently, form the foundation of operator-driven reliability. Each one is within safe scope for trained operators — no specialized tools required.
A structured walk-around before each shift takes 5–10 minutes and catches the most common early-failure signs: fluid leaks, unusual wear, loose guards, abnormal heat or smell. The key word is "structured" — operators need a defined route, specific things to check, and a way to record what they find. An informal glance doesn't produce actionable data. A documented inspection does.
Use a asset inspection checklist to standardize what operators check at each machine. When checks are logged, you build a history that helps predict when equipment is trending toward failure.
Lubrication failures account for roughly 50% of all bearing failures, according to the Machinery Lubrication Institute. Many of those failures happen not because lubrication programs don't exist, but because the interval between technician visits is too long. When operators handle basic lubrication points on a daily or weekly cycle, that gap closes. The task is low-risk, easy to train, and has a direct impact on bearing and motor life.
An operator who notices something unusual but has no clear channel to report it — or no confidence that the report will be acted on — will stop reporting. Building abnormality reporting into the shift routine requires two things: a fast, simple way to log observations (a mobile work request takes under a minute) and visible follow-through by the maintenance team. When operators see their reports turn into work orders and fixes, the behavior reinforces itself.
With digital work requests, operators can raise issues via mobile — including photos — without interrupting production or waiting for a supervisor.
Vibration loosens fasteners. Operators who are trained to spot and correct loose bolts, guards, and fittings within their safe scope prevent the escalation from "minor loose part" to "component failure." The scope must be defined clearly — operators should never adjust anything that requires isolation, electrical work, or specialized alignment tools. But within those boundaries, minor tightening is a high-value, low-risk operator activity.
Dust, debris, and spills accelerate wear and create fire and slip hazards. Operators who maintain a clean work area around their equipment don't just support safety — they make it far easier to spot new leaks, wear patterns, or damage that would otherwise be hidden. Clean equipment is also easier to inspect. In autonomous maintenance programs, cleanliness is always the foundation that everything else builds on.
A good operator checklist is short enough to complete in under 10 minutes and specific enough to be actionable. Here's a proven structure you can adapt for any rotating or production equipment:
When this checklist is run through a digital maintenance checklist system, every completed inspection is timestamped, stored, and visible to the maintenance team — eliminating the paper-based gaps where data gets lost.
Autonomous maintenance is one of the eight pillars of Total Productive Maintenance (TPM). Its core idea is simple: give operators the training, tools, and authority to maintain their own equipment at a basic level — so maintenance technicians can focus on complex, high-value work.
TPM defines autonomous maintenance as a seven-step progression that moves operators from passive machine users to active reliability contributors:
Most organizations don't need to implement all seven steps immediately. Steps 1–3 alone — clean, fix contamination, and set standards — produce measurable results within weeks.
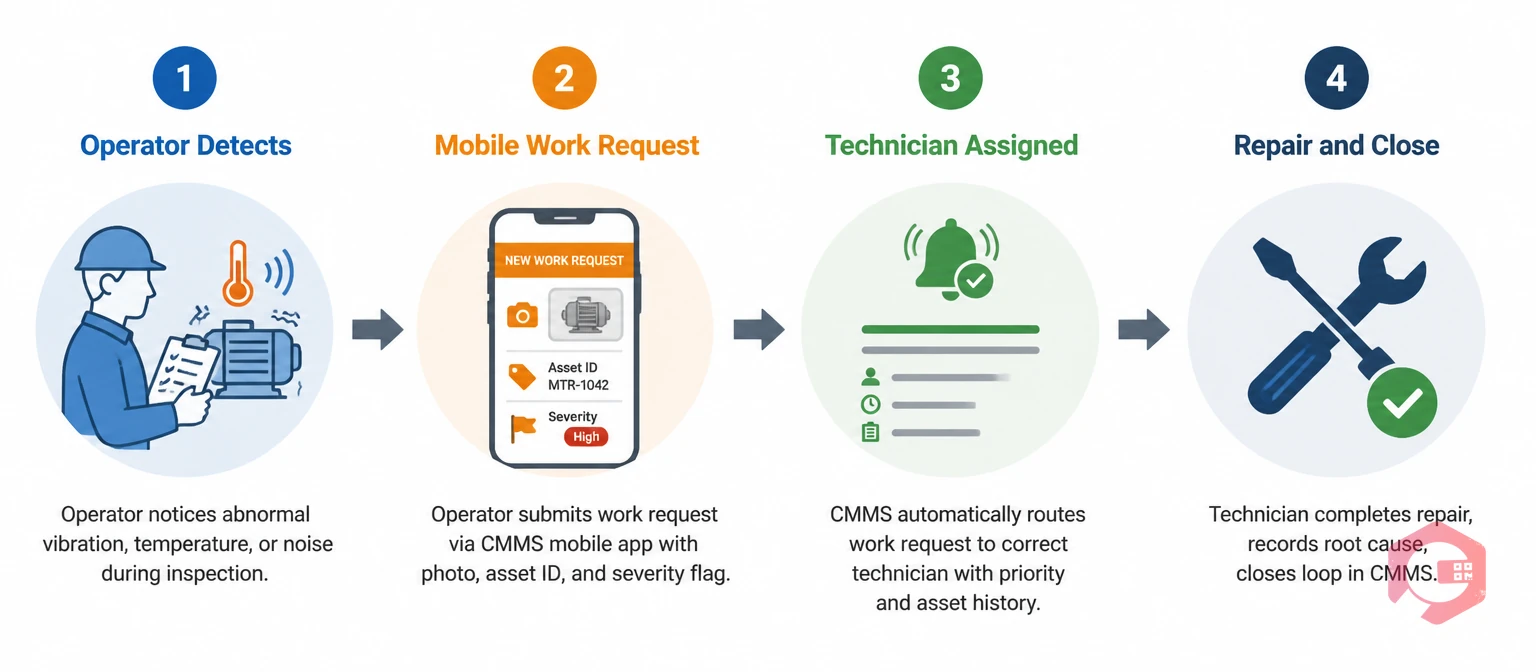
The biggest weakness in operator-led maintenance isn't operator engagement — it's what happens after an operator reports a problem. If the report goes into a paper log, a shared email inbox, or a verbal handoff at shift change, it frequently gets lost, duplicated, or delayed. The operator sees nothing happen. They stop reporting.
A maintenance management system closes that loop. When an operator submits a work request — via mobile, QR code scan, or WhatsApp — it immediately creates a traceable record. The maintenance team sees it, assigns it, and the operator gets notified when the work is done. That closed loop is what builds the culture of reporting that operator-led reliability depends on.
With Cryotos, operators can:
The result is that nothing falls through the cracks between shift changes. Every observation is captured, every report is traceable, and downtime tracking reflects the full picture — including the near-misses that operator reports help prevent.
Teams using Cryotos have reported a 30% reduction in unplanned downtime within the first year of deployment — driven largely by faster detection and response, enabled by operators who are finally equipped to act on what they see.
Operator-driven maintenance (ODM) is a reliability strategy where machine operators take responsibility for basic maintenance tasks — daily inspections, lubrication, cleaning, and abnormality reporting — rather than leaving all maintenance activity to the dedicated maintenance team. It is a core component of autonomous maintenance and Total Productive Maintenance (TPM) programs.
Operators can safely handle visual inspections, basic lubrication, minor tightening within defined torque limits, cleaning and housekeeping, and logging abnormalities. They should not perform tasks requiring lockout/tagout, electrical isolation, disassembly, or precision alignment — those remain with qualified technicians.
The key is making reporting easy and showing visible follow-through. If operators submit reports through a simple mobile form and see those reports converted into work orders that get fixed, they keep reporting. If reports disappear into a black hole, reporting stops. A CMMS with closed-loop work request tracking is the most effective tool for sustaining operator reporting behavior.
Autonomous maintenance is one of the eight pillars of Total Productive Maintenance. It is a seven-step program that progressively trains operators to clean, inspect, lubricate, and maintain their own equipment. The goal is to transfer basic maintenance ownership to operators so that technicians can focus on complex repairs, preventive maintenance planning, and reliability improvement projects.
A CMMS supports operator maintenance by providing digital inspection checklists, mobile work request submission, QR-code-based asset access, and real-time notification when reported issues are addressed. It also gives maintenance managers visibility into inspection completion rates, common abnormality patterns, and root cause trends — turning operator observations into structured reliability data.
Operators are your earliest warning system. When they're trained, equipped with clear checklists, and connected to maintenance through a system that closes every loop, they don't just report problems — they prevent them. Cryotos CMMS gives your operators the tools to move from passive machine users to active reliability partners. See how teams are cutting unplanned downtime by 30% — request a demo today.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











