
Preventing costly downtime in spinning and weaving operations starts with understanding that these machines never stop failing the same way twice — and that reactive maintenance in a textile mill is one of the most expensive habits a plant manager can have. A single unplanned stoppage on a ring frame or rapier loom can wipe out the production margin for an entire shift, cascade into yarn shortages downstream, and push delivery deadlines past the point of recovery.
According to a McKinsey analysis of industrial maintenance practices, manufacturers that move from reactive to preventive and predictive maintenance reduce unplanned downtime by 35–45% and cut maintenance costs by 10–25%. In spinning and weaving, where machines run at 15,000–25,000 RPM and every hour of lost production translates directly to lost revenue, those numbers are the difference between a profitable quarter and a painful one.
This guide covers the specific causes of downtime in spinning and weaving operations, the maintenance strategies that actually prevent it, and how a structured CMMS approach — backed by real-time data — turns reactive firefighting into planned, measurable reliability.

Textile mills run on tight delivery contracts and thin margins. When a ring frame or air-jet loom goes down, the cost isn't just the repair — it's the ripple effect across the entire production floor.
According to a Plant Engineering report on the true cost of downtime, industrial facilities lose an estimated $50 billion annually to unplanned equipment failures — and textile mills, with their continuous multi-shift operations, are among the hardest hit.
Not all machines fail equally. In most spinning and weaving operations, 20% of the asset base drives 80% of the unplanned downtime. Knowing which assets are in that top tier — and maintaining them differently — is the foundation of a downtime prevention strategy.
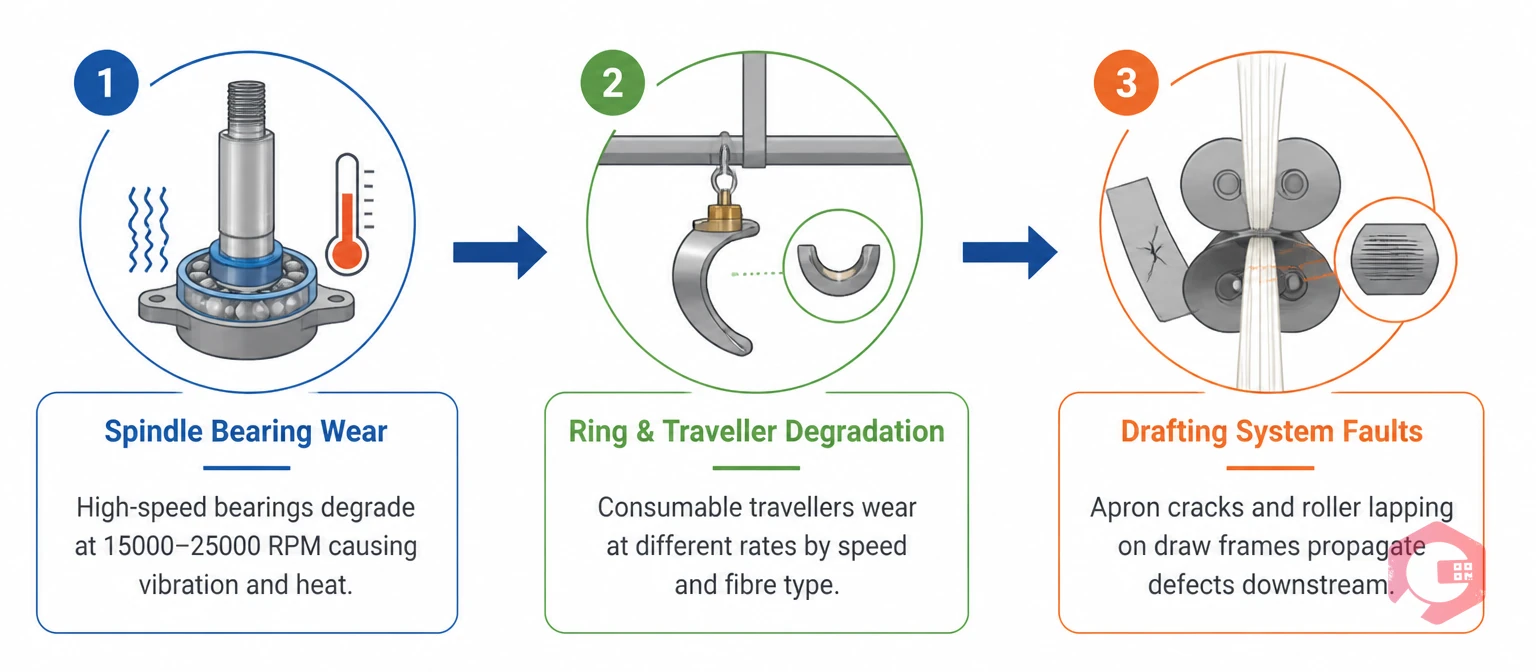
Spinning machines fail through predictable mechanisms. Understanding what actually causes stoppages in ring frames, open-end rotors, and draw frames lets you design maintenance programs that intercept failures before they reach the production floor.
Spindle bearings are the most failure-prone component in a ring spinning frame. At operating speeds of 15,000–25,000 RPM, even minor bearing degradation causes vibration, heat buildup, and accelerating wear. The problem is that spindle bearing wear develops gradually over thousands of hours — it's detectable with vibration sensors long before it causes a spindle failure or yarn break cascade. Most mills that experience frequent spindle failures don't have a bearing problem; they have a PM interval problem. Bearing inspection and lubrication intervals set by the original equipment manufacturer are baselines, not fixed rules — actual intervals should be calibrated to your mill's specific spindle speed, ambient temperature, and fibre type.
Travellers are consumable components, but they're consumed at very different rates depending on spindle speed, yarn count, and fibre characteristics. Mills running fine counts on high-speed frames replace travellers every two to four days. Mills running coarser counts at lower speeds may get two weeks or more. Without a data-driven replacement schedule — one that tracks actual wear against production parameters — traveller failure becomes a primary driver of yarn breaks and machine stoppages. The fix is straightforward: log traveller replacement in your preventive maintenance software with the spindle speed and count, and let the data set the interval.
Apron cracks, top roller lapping, and trumpet wear on draw frames and roving frames cause quality defects and ultimately machine stoppages. These faults tend to propagate through the spinning process — a lapping issue on a draw frame shows up as thick-and-thin places in the yarn several machines downstream. Condition-based inspection of drafting systems — checking apron condition, roller wrap patterns, and trumpet wear at defined usage intervals — catches these problems before they reach the ring frame.
Weaving machines fail differently from spinning machines — they are more mechanically complex, more sensitive to timing, and more dependent on consistent yarn quality from upstream. Most weaving shed downtime is traceable to a small number of recurring fault categories.
On air-jet looms, weft insertion faults account for the majority of machine stoppages in most weaving sheds. Nozzle wear, valve timing drift, and thread sensor malfunctions cause weft breaks and subsequent automatic stoppages. On rapier looms, gripper wear, rapier tape damage, and feeder timing issues are the equivalent failure modes. In both cases, the failure is progressive and detectable. Air nozzle wear can be measured. Valve response times can be benchmarked. Gripper condition can be checked. The problem in most weaving sheds is that these checks happen reactively — after the fault — rather than proactively on a defined schedule.
The shedding mechanism — whether cam, dobby, or Jacquard — controls warp thread separation for each pick. Cam follower wear, dobby knife wear, and Jacquard hook failures are all progressive and measurable. They typically signal themselves through increasing machine vibration, rising power consumption, and subtle changes in shed geometry before they cause a hard failure. Vibration analysis and current monitoring on the shedding drive motor, combined with scheduled cam inspection intervals, catch these failures at a fraction of the cost of an unplanned stoppage.
Warp beam bearing wear and tension regulator faults cause warp breaks and fabric defects. In mills running fine fabrics and tight tolerances, even small deviations in warp tension cause quality problems that manifest at inspection rather than at the loom — by which point the defective fabric is already woven. Scheduled warp beam bearing inspection and tension calibration, tied to beam change points, are standard practice in well-run weaving sheds.
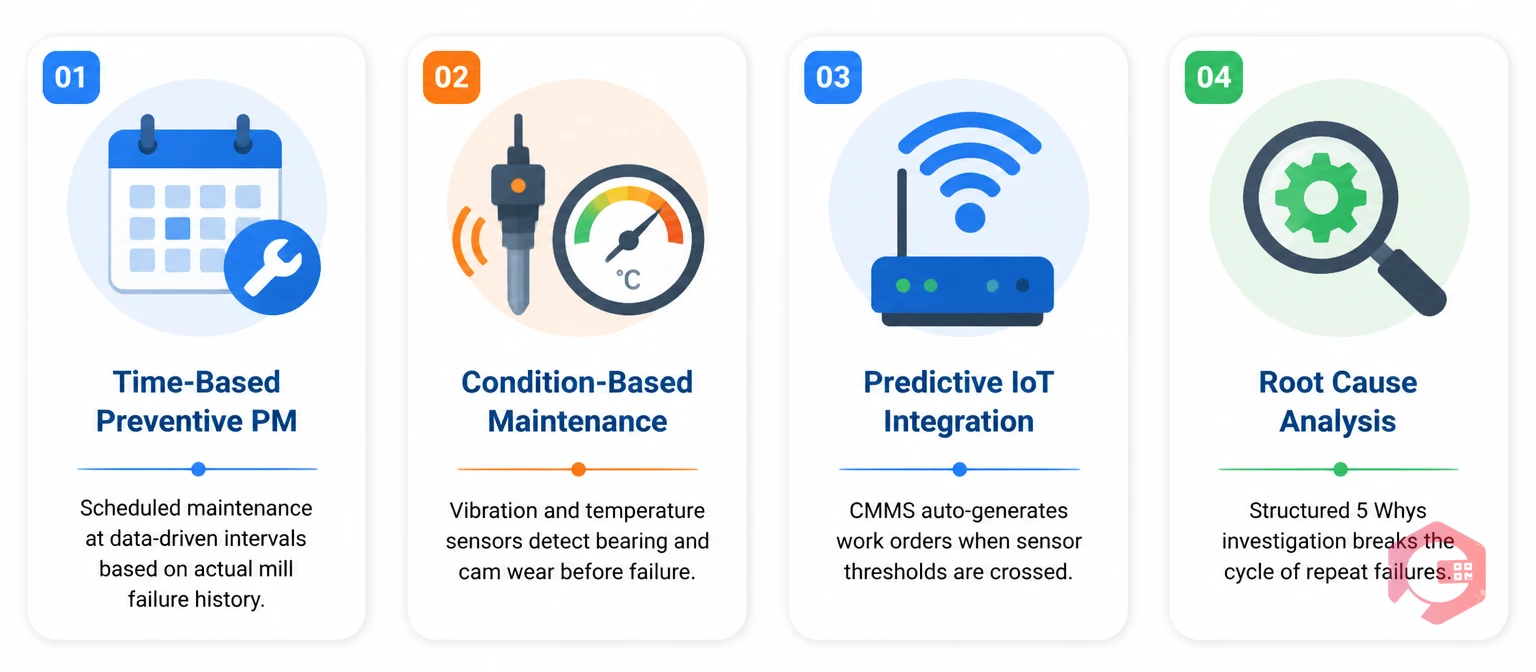
Not all maintenance is equally effective at preventing downtime. The strategy you choose for a given machine should match that machine's failure mode, not a generic industry template.
Time-based PM is the right approach for machines with predictable wear patterns — ring travellers, loom shuttle checks, belt drives, and lubrication points. The key discipline is setting intervals based on actual failure history from your mill, not OEM defaults. OEM intervals are calibrated for average conditions; your mill's specific speeds, fibre types, and ambient conditions will give you a different interval. Use your maintenance checklists to log PM completion and failure data against intervals — over six to twelve months, the data will tell you whether your current intervals are too long or too short for each specific asset.
For high-criticality assets with progressive failure modes — spindle bearings, compressor rotors, loom cam followers — condition-based maintenance is more effective than fixed intervals. Vibration sensors on spindle housings, temperature monitoring on compressor bearings, and current draw monitoring on loom drive motors all provide early warning signals that time-based PM misses. Condition-based maintenance requires investment in sensor infrastructure, but the payback is rapid in spinning and weaving operations where critical asset failures carry high production cost.
The most advanced mills now connect their CMMS directly to IoT sensors on critical assets. When a vibration threshold is crossed on a spindle bearing housing or a temperature spike appears on a compressor bearing, the system automatically generates a work order — before any human notices anything wrong. This is the shift from scheduled maintenance to truly condition-triggered maintenance. Cryotos connects to SCADA, PLC, and edge devices via its IoT meter reading feature, turning sensor data directly into work orders without requiring a maintenance planner to monitor dashboards.
In most spinning and weaving operations, the same five to ten failure modes account for the majority of unplanned downtime. If your team is responding to the same bearing failure on the same ring frame every three weeks, the problem isn't the bearing — it's the PM interval, the lubrication specification, the spindle speed setting, or something upstream in the drafting system. Structured root cause analysis on every repeat failure, built into the work order closure workflow, breaks the cycle. Cryotos includes a built-in 5 Whys analysis tool that forces systematic investigation before a repeat failure work order can be closed.
A CMMS is the operational backbone that makes all of the above strategies practical at scale. Without software, PM schedules drift, work order histories are incomplete, spare parts run out at the worst moment, and downtime data is too fragmented to act on. With the right CMMS, every machine in the spinning room and weaving shed has a complete, visible maintenance history — and every failure feeds back into better PM intervals.
Fixed-calendar PM schedules don't work for spinning and weaving machines that run different hours depending on production demand. A ring frame running three shifts at full capacity accumulates spindle hours at twice the rate of one running a single shift. Runtime-based PM scheduling — triggered by spindle hours, loom picks, or production metres rather than calendar days — ensures that maintenance actually happens when the machine needs it, not when the calendar says it's due. Cryotos supports both static (calendar-based) and dynamic (usage-based) PM triggers, with either/or scheduling so the first condition reached automatically generates the work order.
You can't reduce downtime you can't measure. The first step in most downtime reduction programs is simply installing accurate tracking — not sophisticated prediction, just consistent logging of when machines stop, why they stop, and how long they're down. Cryotos's downtime tracking module gives spinning and weaving maintenance managers a drill-down view from plant level to individual machine — with MTBF, MTTR, BDO, and availability percentage calculated automatically from work order timestamps. No spreadsheets, no manual calculations.
Running out of a critical spare part during an unplanned breakdown is one of the most preventable causes of extended downtime. Most spinning and weaving mills that track their downtime carefully find that 15–25% of their MTTR is not repair time — it's parts hunting time. Cryotos's inventory management module links spare parts directly to the assets that consume them, with minimum stock thresholds that trigger reorder alerts before stockouts happen. Ring travellers, apron cords, loom cam followers, and bearing sets for critical machines should all have defined minimum quantities linked to their respective asset records.
In a spinning room or weaving shed, maintenance technicians are rarely at a desk. The ability to receive, action, and close work orders from the machine floor — using a mobile app that works offline in areas with poor connectivity — directly reduces response time and improves the accuracy of maintenance records. Cryotos's mobile app supports offline operation with automatic sync, QR code asset scanning for instant machine identification, and photo and video attachment for fault documentation.
The most effective downtime prevention programs in spinning and weaving mills don't start with technology — they start with data. Before you can prevent downtime, you need to understand where it's coming from.
Before changing any maintenance intervals or adding any technology, spend four to six weeks logging every unplanned stoppage: the machine, the fault type, the time to first response, the time to repair, and the parts consumed. Most mills that do this exercise for the first time are surprised by how concentrated their downtime is. Five to ten failure modes on ten to fifteen machines typically account for the majority of lost production hours. That concentration tells you exactly where to focus first.
Classify every machine in your spinning room and weaving shed by criticality: critical (failure stops production or cascades to multiple machines), important (failure degrades output quality or speed), and routine (failure has limited production impact). Your highest-priority PM investment goes to the critical tier — compressors, humidification systems, ring frames that feed critical downstream processes, and air-jet looms running time-sensitive orders. Use asset tracking with QR codes to give every machine a unique digital identity, accessible instantly from the floor.
Use the downtime data from Step 1 to set PM intervals for your highest-downtime assets. For each recurring fault, the PM interval should be shorter than the average time between failures — with enough margin to catch the fault before it reaches the production line. For assets without failure history yet, start with OEM recommendations and adjust based on your first six months of data.
Once your PM program is running, track MTBF, MTTR, PM compliance rate, and unplanned downtime hours per machine, per department, and per shift. Review monthly. A rising MTBF on a previously troublesome machine is a clear signal that the PM interval is working. A stagnant or declining MTBF means the interval needs tightening or the root cause hasn't been addressed. The BI Dashboard in Cryotos surfaces all of these metrics in real time without requiring manual report assembly.
Spindle bearing wear, ring traveller degradation, and drafting system faults — particularly apron cracking and top roller lapping — are the most common causes of unplanned downtime in ring spinning mills. Open-end mills see similar issues with rotor bearing wear and trash accumulation in opening rollers. In both cases, the failures are progressive and preventable with properly timed PM schedules and condition monitoring.
Service frequency depends on loom type, weaving speed, and fabric type. Air-jet looms running dense fabrics at high speeds need more frequent nozzle and valve inspection than rapier looms running lighter fabrics. As a starting point, follow OEM service schedules for each system — shedding, weft insertion, warp control — and adjust intervals based on your mill's actual fault history after three to six months of tracking. Runtime-triggered PM, based on loom picks rather than calendar days, is more accurate than fixed-interval scheduling in most weaving sheds.
Yes, but selectively. IoT sensors on air compressors, loom drive motors, and cam follower systems can detect developing faults weeks before they cause a stoppage. The strongest return comes from deploying sensors on assets where the failure cost is highest and the failure mode is detectable — compressor bearing temperature, loom drive motor vibration, and air nozzle pressure drop. Not every machine needs IoT monitoring; focus sensor investment on the machines whose failure has the highest production impact.
The five most important KPIs for textile maintenance teams are MTBF (mean time between failures), MTTR (mean time to repair), planned maintenance percentage, machine availability, and downtime by failure mode. Track them at the machine level, not just the plant level — a plant-level OEE of 75% can hide one machine running at 40% availability and another at 95%. Machine-level KPIs tell you where to act; plant-level KPIs tell you whether you're making progress.
A CMMS prevents downtime through four mechanisms: it automates PM scheduling so maintenance happens when the machine needs it, not when someone remembers; it tracks downtime and failure modes so you can see patterns and adjust PM intervals; it manages spare parts inventory so critical parts are always on hand; and it provides technicians with complete machine history at the point of work, reducing diagnosis time and repeat failures. Cryotos CMMS delivers all four in a single platform built for manufacturing operations, with reported results of 30% downtime reduction and 25% faster repair times across industries including textile manufacturing.
Preventing downtime in spinning and weaving operations isn't about buying the latest sensor technology or implementing the most sophisticated maintenance strategy. It starts with knowing exactly which machines are driving your downtime, why they're failing, and whether your current PM intervals are actually intercepting those failures before they reach production. Most mills that work through that analysis find the answer is no — and that the path to 30% lower downtime runs through better data, better PM intervals, and better spare parts management rather than through new equipment.
If your maintenance team is still logging breakdowns on paper or managing PM schedules in spreadsheets, Cryotos CMMS gives spinning and weaving operations the tools to build a structured, data-driven maintenance program — from machine-level PM scheduling to real-time downtime KPIs to IoT-triggered work orders. Book a free demo today and see how mills like yours are cutting unplanned downtime and protecting production margins.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











