
Real-time alerts during preventive maintenance execution prevent equipment failure by automatically converting abnormal inspection readings into tracked work orders before anyone has to remember to follow up. When a technician measures a vibration reading of 12 mm/s against an 8 mm/s threshold and enters it into a preventive maintenance software platform, the system immediately generates an alert work order, assigns it to the right team, and surfaces it on the maintenance dashboard — in seconds, without any manual decision.
According to a Plant Engineering study on maintenance costs, unplanned downtime costs industrial manufacturers an average of $260,000 per hour. Most of those failures were detectable during a scheduled PM inspection — the gap was in the response, not the inspection itself. Real-time alert work orders close that gap.
This guide explains how alert work orders are triggered during PM execution, how to configure thresholds correctly, what a monitoring dashboard should track, and how Cryotos CMMS makes the entire flow work automatically.

An alert work order is automatically generated by a CMMS the moment a technician submits a reading or observation that falls outside a pre-configured acceptable range during a PM inspection. No supervisor needs to review it. No technician needs to escalate it manually. The system acts on the data the instant it is entered.
This is a meaningful operational distinction. Standard corrective work orders are created manually — someone notices a problem, decides it needs a work order, and creates one. Alert work orders are created by the system, triggered by data, before a human decision is required.
| Work Order Type | How Created | Trigger | Timing | Primary Use |
|---|---|---|---|---|
| Planned PM | Automatically by schedule | Calendar or meter trigger | Before condition is known | Routine inspection and servicing |
| Alert Work Order | Automatically by data threshold breach | Abnormal reading during PM | During inspection — before failure | Targeted corrective response to a detected anomaly |
| Corrective Work Order | Manually by technician or supervisor | Observed failure or complaint | After failure or after manual review | Repair of a known, existing fault |
| Emergency Work Order | Manually under urgency | Asset breakdown mid-production | After unplanned failure | Restore operation as fast as possible |
Alert work orders occupy the critical middle position: they are triggered before failure, during a scheduled inspection, without waiting for a human to notice and escalate. That is the window where intervention costs the least and prevents the most.
Preventive maintenance checklists create inspection discipline and generate historical records. Without an alert trigger layer, however, the data they produce is only as useful as the process that acts on it — and that process regularly fails in predictable ways.
The most common failure modes in facilities that run PMs without automated alert generation are: delayed response, where abnormal readings sit in a paper log or spreadsheet until the next supervisor review; inconsistent escalation, where whether an out-of-range reading gets escalated depends on the individual technician's judgment rather than a system rule; and lost data, where readings entered in a mobile app but never linked to a follow-up task simply disappear from operational visibility.
The underlying problem is structural. Standard PM checklists treat inspection and response as two separate, sequential processes. Alert work orders collapse them into one. When the reading is abnormal, the response begins immediately — not after a handover, not after a weekly report, not after a supervisor notices a paper log.
Research by McKinsey on maintenance digitisation found that facilities with automated condition response — triggered at the point of data capture — reduce unplanned downtime by 30–50% compared to those relying on manual escalation after scheduled inspections. The inspection work is equivalent; the automated response is the differentiator.
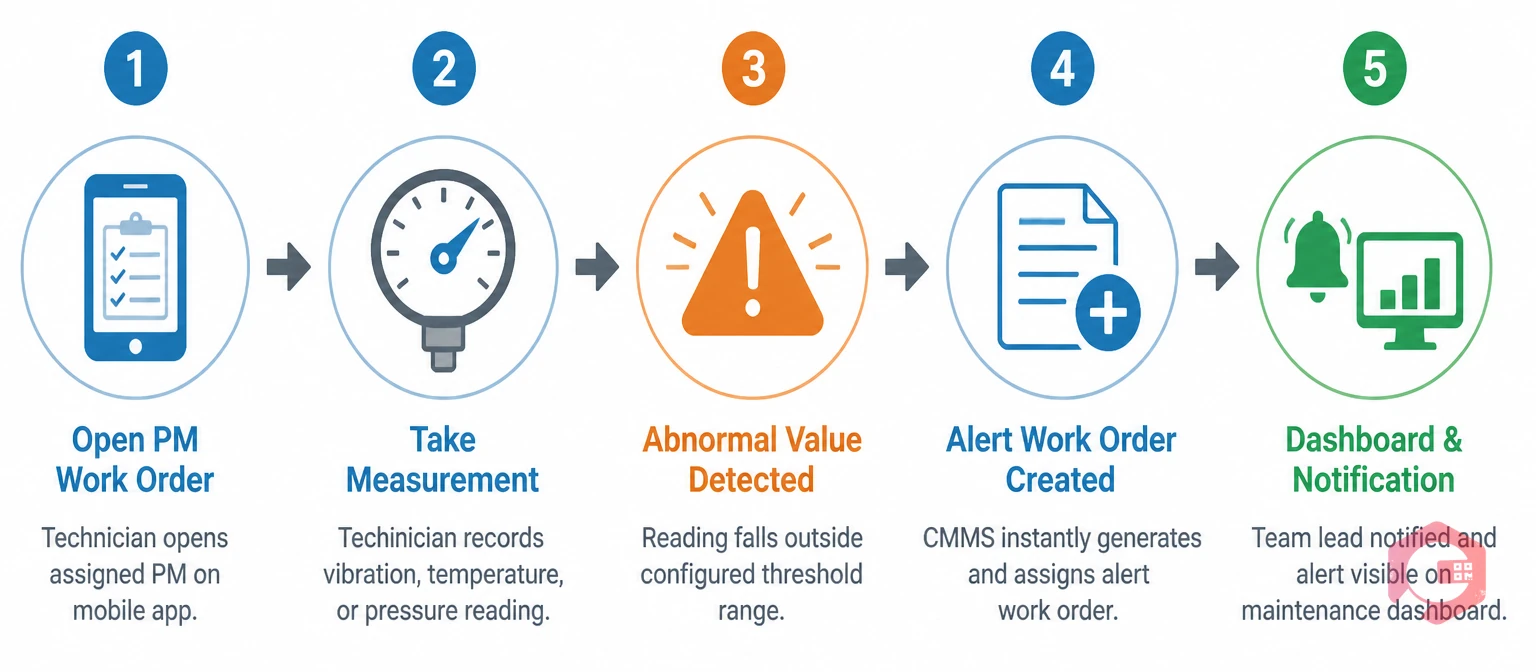
The mechanism is straightforward. When a maintenance team builds a PM checklist in a CMMS with alert work order capability, each measurement task can be assigned acceptable ranges — a lower limit, an upper limit, or both. When a technician submits a reading that falls outside those limits during inspection execution, the system immediately creates an alert work order.
The step-by-step flow in a properly configured CMMS works like this. First, the technician opens the assigned PM work order on the mobile app and works through the checklist. When a measurement task is reached — bearing vibration, temperature, pressure, oil level — the technician enters the observed value. If the value falls within the configured acceptable range, the task is marked complete and the technician moves on. If the value falls outside the acceptable range, the CMMS instantly creates a new alert work order linked to that PM task, assigns it to the relevant team based on predefined rules, and pushes a notification to the team lead.
The entire sequence — from abnormal reading entry to alert work order creation to assignment to dashboard visibility — takes seconds. The work order management system handles every step automatically. Human judgment is preserved for what it does best: physically resolving the identified issue.
The original PM work order continues to completion in parallel. The technician finishes the scheduled inspection. The alert work order runs concurrently as a separate tracked item, with its own priority, assigned team, and resolution deadline.
The effectiveness of alert work orders depends entirely on the quality of the thresholds that trigger them. Thresholds set too wide miss real problems. Thresholds set too narrow generate alert fatigue, where technicians start ignoring notifications because too many are false positives.
A practical framework for configuring thresholds uses three reference sources: OEM specifications, industry standards, and historical performance data for your specific assets in your specific operating environment.
For vibration measurements, ISO 10816 provides class-based velocity limits for rotating machinery by machine type and mounting condition. For temperature, OEM manuals typically specify operating ranges with warning and alarm thresholds. For pressure and flow measurements, process engineers define normal operating ranges based on system design. These values form the starting point — but they should be adjusted based on your historical data. An asset that has operated reliably at the upper edge of its OEM spec for years may warrant a tighter threshold than the spec suggests, because any deviation from that historical norm is more significant than the raw number implies.
| Measurement Type | Primary Reference | Warning Threshold | Critical Threshold | Recommended Alert Priority |
|---|---|---|---|---|
| Bearing vibration (mm/s) | ISO 10816 class | 80% of upper limit | At or above upper limit | Medium / High |
| Motor winding temperature (°C) | OEM spec + insulation class | OEM warning temp | OEM alarm temp | Medium / Critical |
| Oil pressure (bar) | System design spec | ±10% of nominal | ±20% of nominal | Medium / High |
| Coolant temperature (°C) | OEM and process spec | OEM warning temp | OEM alarm temp | Medium / Critical |
| Insulation resistance (MΩ) | IEC 60034 / historical baseline | Below 20 MΩ | Below 5 MΩ | High / Critical |
Configure two-band thresholds wherever possible — a warning band that generates a medium-priority alert and a critical band that generates a high-priority alert with immediate escalation. This gives maintenance teams proportionate responses rather than treating every alert as equally urgent. The IoT sensor deployment checklist covers validation steps for sensor-driven thresholds as well.
Generating alert work orders is only half the equation. Monitoring them through a maintenance dashboard closes the loop and ensures that no alert ages without resolution.
A maintenance dashboard configured for alert work order monitoring should show open alert work orders by priority, filtered by asset, location, and assigned team; alert age, meaning the time elapsed since the alert was generated, flagged when it exceeds the target response time for its priority level; resolution rate, the percentage of alert work orders closed within the target window over the past 30 days; and repeat alert assets, any asset generating alert work orders across multiple consecutive PM cycles.
The repeat alert view is particularly valuable. An asset that triggers a warning-band alert three PMs in a row is showing a deterioration trend even though no individual reading crossed the critical threshold. A maintenance dashboard that surfaces this pattern gives the team a data-backed case for a reliability intervention before the asset fails outright. This feeds directly into reliability-centered maintenance decision-making.
Escalation rules should be configured so that unresolved alert work orders automatically notify higher-level supervisors after a defined time window. A high-priority alert that has not been acknowledged within two hours should escalate to the maintenance manager. A critical alert should escalate within 30 minutes. These escalation chains ensure that every alert reaches someone with authority to act, regardless of shift changes or technician availability.
The BI dashboard in Cryotos aggregates all of this data — open alerts, resolution rates, alert age distribution, repeat assets — in real time, without requiring any manual report compilation.
A facility maintenance team at a food processing plant runs a quarterly PM on a 200-ton chiller unit. The Cryotos CMMS checklist includes a bearing vibration measurement task. The acceptable range is configured at 0 to 8 mm/s based on ISO 10816 guidelines for that machine class, with a warning band at 6–8 mm/s and a critical threshold above 8 mm/s.
During the inspection, the technician measures a reading of 12.4 mm/s. The moment the reading is submitted in the Cryotos mobile app, the system generates a high-priority alert work order with the task description "Bearing vibration out of range — inspect and assess chiller bearing condition." The work order is automatically assigned to the mechanical maintenance team. The team lead receives a push notification within 30 seconds of the reading being entered. The alert work order appears immediately on the maintenance dashboard.
The mechanical team responds within two hours, inspects the bearing, and confirms early-stage wear. The bearing is replaced during the same shift. Total downtime: 3.5 hours of planned maintenance work.
Without the alert work order trigger, the vibration reading would have been reviewed at the end-of-week PM report meeting. Based on the wear rate observed, the bearing would likely have failed within five to seven days, causing an unplanned shutdown estimated at 8–12 hours of lost production plus emergency parts procurement costs. The alert work order converted a reactive failure into a planned repair — because the system acted on the data the moment it was captured.
Cryotos also links each alert work order back to the specific PM checklist reading that triggered it, creating a complete audit trail from abnormal observation to resolution that is accessible in the asset tracking history and exportable for compliance reporting.

Integrating alert work order generation into PM execution delivers measurable operational improvements across several dimensions. Response time drops because the alert reaches the right team within seconds of the abnormal reading, not after a shift change or report review. Resolution accountability increases because every alert is a tracked work order with an assigned owner, a priority level, and a deadline — it cannot quietly disappear. Documentation improves because each alert work order contains the reading that triggered it, the PM task it was linked to, the response time, the work performed, and the outcome — a complete record for root cause analysis and compliance purposes.
At the program level, facilities that run alert work orders as a standard part of their PM process consistently shift their maintenance ratio toward planned work. According to Reliability Plant benchmarks, the target is 80% planned versus 20% reactive. Alert work orders are one of the most direct mechanisms for achieving that ratio — by catching developing problems during scheduled inspections rather than after unplanned failures. Cryotos customers report a 30% reduction in downtime and 25% faster repair times as direct outcomes of this approach.
Alert work orders also surface patterns over time. When the same asset generates warning-band alerts on three or four consecutive quarterly PMs, the maintenance dashboard makes that visible. A reliability engineer reviewing the data can initiate a targeted assessment or adjust the PM frequency before the asset fails. This kind of data-driven maintenance interval optimization is what distinguishes a proactive maintenance program from one that simply executes a fixed schedule. Use the MTBF calculator to quantify the improvement in asset reliability between periods.
Cryotos CMMS has alert work order generation built directly into its PM module. When building a PM checklist, maintenance managers configure acceptable ranges for any measurement task — vibration, temperature, pressure, oil level, or any custom parameter. When a technician submits an out-of-range reading on the Cryotos mobile CMMS app, the system automatically generates the alert work order, assigns it based on configured rules, and pushes the notification to the relevant team — all without manual intervention.
The generated alert work order appears immediately in the Cryotos maintenance dashboard, where it can be tracked by priority, age, asset, location, and assigned technician. Escalation rules can be configured so that unresolved alerts automatically notify higher-level supervisors after a defined time window. Alert work orders are fully linked to the PM checklist reading that triggered them and to the asset record, creating a continuous audit trail accessible in the report builder and available for export.
Cryotos also supports WhatsApp integration for alert notifications, so technicians and supervisors receive alerts on the communication channel they already use — without needing to check a separate app. If your facility is still relying on manual escalation after PM inspections, the gap between reading and response is costing you in unplanned downtime and missed intervention windows. Cryotos closes that gap automatically. Request a demo to see how alert work order generation works for your asset types and inspection workflows.
A corrective work order is created manually when someone identifies a fault or failure. An alert work order is generated automatically by the CMMS the moment a technician submits an out-of-range reading during a PM inspection. The key distinction is timing and trigger: alert work orders fire before failure, at the point of data capture, without requiring any human decision to escalate.
Yes. A well-configured CMMS supports two-band threshold settings — a warning band that generates medium-priority alert work orders and a critical band that generates high-priority work orders with immediate escalation. This gives maintenance teams proportionate responses rather than treating every alert as equally urgent. Cryotos supports both bands for any measurement parameter in a PM checklist.
Threshold values should be defined by reliability engineers or experienced maintenance managers who understand the operational significance of each parameter for each asset class. Starting references are OEM specifications and industry standards such as ISO 10816 for vibration. These should be refined using historical performance data for your specific assets in your operating environment. CMMS administrators enter the values; the technical decisions come from engineering expertise.
A multi-site CMMS like Cryotos provides a centralized maintenance dashboard that aggregates alert work orders across all locations. Managers can filter by site, asset type, priority, or alert age. Escalation rules can be configured per site or globally. This gives corporate maintenance managers real-time visibility into alert status across all facilities without separate logins or manual report consolidation.
Alert work orders generated from data entry errors can be closed with a disposition code such as "data entry error" without completing any physical work. The closed work order stays in the audit trail, maintaining a complete record. Cryotos supports sanity checks on readings — values outside a physically plausible range are flagged before submission rather than triggering an alert work order, which reduces false alerts from entry errors.
Preventive maintenance inspections are only as valuable as the system built to respond to what they find. When a technician records an abnormal reading, the window to prevent a failure is open — but it does not stay open indefinitely. Real-time alert work orders close the response gap automatically. The combination of well-configured thresholds, automated alert generation, and a dashboard built for resolution tracking is what separates facilities that use PM data to prevent failures from those that only use it to document them. Explore Cryotos CMMS to see how the full alert workflow fits your operations.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











