
A repeat failure is any breakdown on the same asset, caused by the same underlying fault, that occurs more than once. The first time a pump seal fails, it is a maintenance event. The second time the same seal fails on the same pump, within the same operating conditions, it is a systems failure — evidence that the repair closed the symptom without ever addressing the cause. According to the Society for Maintenance and Reliability Professionals (SMRP), repeat failures account for 30–40% of all reactive maintenance work orders in operations without a structured root cause analysis process. That figure represents a significant proportion of maintenance budget, technician time, and production downtime that is entirely preventable — but only if the maintenance team has a process that distinguishes between closing a work order and actually solving a problem. This guide explains why repeat failures happen, how to identify them in your work order data, and how to build the process and CMMS discipline that breaks the fix-it-again cycle permanently.
Key Takeaways
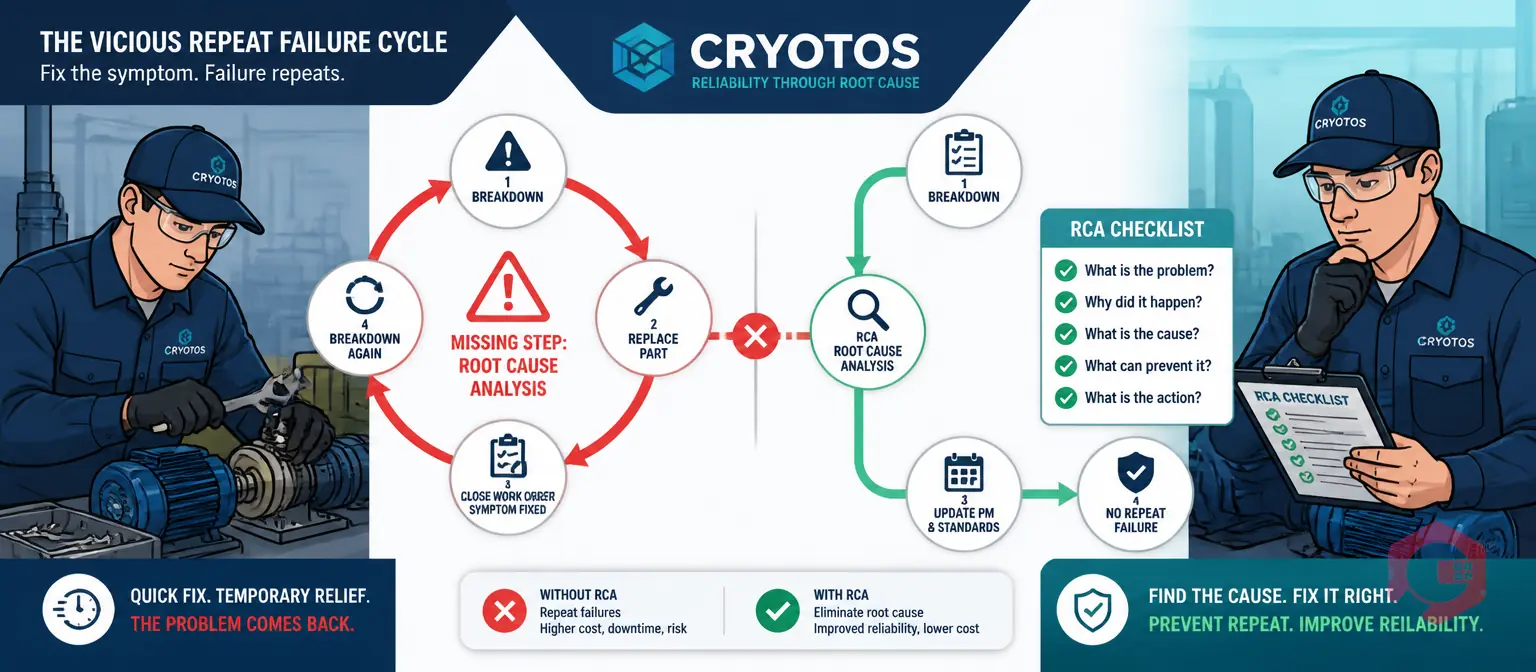
Repeat failures do not happen because maintenance technicians are careless. They happen because the maintenance system — the combination of work order process, failure data capture, RCA practice, and PM schedule — is structured to close work orders, not to eliminate failure causes.
The most common cause is symptom-level repair without root cause investigation. When a technician attends a fault, replaces the failed component, and closes the work order as "repaired," the system records a successful maintenance event. But if the failed component failed due to misalignment, contamination, incorrect installation torque, or a lubrication frequency gap — and none of those conditions were addressed — the same component will fail again, typically within the same operating cycle. The work order closed. The failure cause remained.
The second cause is PM inadequacy — schedules that are theoretically correct but practically insufficient. A PM interval set from manufacturer recommendations without adjustment for actual operating conditions will consistently under-maintain critical wear points. Bearings that should be lubricated every 250 hours on a high-duty application are over-maintained at 500 hours; seals exposed to aggressive cleaning chemicals degrade faster than OEM schedules assume. According to Plant Maintenance Resource Center's research on PM optimisation, up to 40% of PM intervals in typical maintenance programmes are mismatched to actual asset operating conditions — producing either wasteful over-maintenance or repeat failures from under-maintenance.
The third cause is incomplete repair. A drive belt that failed due to misalignment is replaced without correcting the alignment; the new belt fails faster than the original. A seal replaced without flushing the contaminated lubrication circuit fails again when contaminated fluid reaches the new seal. The repair was technically competent but diagnostically incomplete.

Repeat failures are visible in your work order history — but only if the data is structured well enough to surface them. Three signals reliably indicate a repeat failure pattern.
The first is the same fault code on the same asset ID appearing more than twice within a 90-day rolling window. An asset generating three "seal failure" work orders in 90 days is not experiencing bad luck — it is experiencing an unresolved failure cause. Run this query on your reactive work orders monthly using the report builder — sort by asset ID and fault code, count occurrences, and flag any combination above two.
The second is a declining MTBF trend on a specific asset. If Pump P-07 had a 180-day MTBF in Q1 and a 90-day MTBF in Q3, the intervals between failures are shrinking — a classic repeat failure signature. Use the MTBF calculator to track failure frequency trends at the asset level; a declining trend over two consecutive quarters is a mandatory trigger for a formal repeat failure investigation.
The third is a high ratio of reactive to planned work orders on a specific asset. An asset generating more reactive work orders than planned PM work orders is in an uncontrolled reliability state — the planned maintenance programme is not preventing the failures appearing as reactive calls. This ratio is the simplest leading indicator of a repeat failure problem before the formal MTBF trend becomes visible.
| Repeat Failure Symptom | Typical Root Cause | Correct Intervention |
|---|---|---|
| Same seal fails repeatedly on pump | Misalignment, contaminated lube circuit, or incorrect installation torque | Alignment check + lube flush at every replacement; torque spec added to PM checklist |
| Drive belt fails before PM interval | Pulley misalignment or tension incorrect at last replacement | Alignment and tension check added as mandatory steps at every belt replacement |
| Bearing failure recurring on motor | Lubrication frequency too low for actual duty cycle or wrong grease spec | PM interval shortened; grease spec verified against operating temperature and load |
| Circuit breaker tripping repeatedly | Upstream load imbalance or loose connection causing thermal cycling | Load balance audit; connection inspection added to PM; breaker replacement alone is insufficient |
| Filter blockage recurring faster than PM interval | Process change increased particulate load beyond original design assumption | PM interval shortened; process change documented in asset record |

Breaking the repeat failure cycle requires three changes to how the maintenance system operates — not just how individual technicians work.
Make RCA mandatory at work order close-out on reactive jobs. If the CMMS work order close-out flow for reactive jobs requires a completed root cause analysis before the work order can be marked closed, RCA stops being optional. Technicians document the fault, the immediate cause, the contributing factors, and the corrective action in the work order record every time. The root cause analysis module embedded in Cryotos's work order close-out flow enforces exactly this — the work order cannot be closed without a cause code and RCA summary, building an institutional knowledge record that persists in the asset's history and feeds future PM improvements.
Treat every repeat failure as a PM programme failure, not an equipment failure. When the same fault recurs on the same asset, the default assumption should be that the PM schedule — its interval, its task list, or its execution quality — is inadequate, not that the equipment is unusually unreliable. This reframe changes the investigation question from "why did this component fail again?" to "what is the PM programme failing to prevent, and why?" That question almost always leads to a specific, actionable answer. Use the root cause analysis investigation checklist to structure the PM review — it forces a systematic examination of task completeness, interval adequacy, and execution quality as separate diagnostic dimensions.
Close the loop between RCA findings and PM schedule updates. An RCA that produces a finding but does not update the PM schedule has not broken the cycle — it has documented the failure without preventing the next one. Every RCA that concludes with a PM-related cause must generate a specific PM change: an interval adjustment, a new task added to the checklist, a parts substitution, or a specification clarification. That change must be implemented in the preventive maintenance software before the work order is formally closed. The asset's work order history then contains a traceable record: failure observed → RCA conducted → PM updated → subsequent failure frequency measured.
Root cause analysis is reactive — it investigates a failure that has already happened. Failure Modes and Effects Analysis (FMEA) is the proactive counterpart — a structured technique that identifies potential failure modes on critical assets before they occur, assesses their likelihood and consequence, and designs maintenance tasks that specifically target the highest-risk failure modes.
For assets with a history of repeat failures, an FMEA review is the correct intervention after RCA has identified the failure mode pattern. The RCA tells you what has been failing; the FMEA tells you what else could fail by the same mechanism, and what the PM programme needs to include to prevent it. According to Reliable Plant's research on PM programme effectiveness, maintenance teams that combine RCA on reactive failures with FMEA on critical assets reduce their repeat failure rate by up to 60% over 18 months compared with teams relying on RCA alone. The FMEA output feeds directly into the PM task list: each identified failure mode with a high Risk Priority Number (severity × occurrence × detectability) becomes a PM task, with frequency set by the occurrence score. This transforms the PM programme from a collection of manufacturer-recommended tasks into a reliability-engineered schedule targeted at the specific failure modes that have actually occurred on each critical asset.
Preventing repeat failures requires the maintenance system to enforce RCA at every reactive work order close-out, make failure history visible at the asset level, and translate RCA findings into PM schedule changes without a separate manual process. Cryotos's CMMS supports all three.
The work order management system enforces mandatory cause code selection and RCA summary completion before any reactive work order can be marked closed — eliminating the most common reason repeat failures persist, which is that the first failure was closed without ever being diagnosed. Every cause code and RCA summary is stored against the specific asset record in the work order history, creating a searchable failure library that any technician can consult before attending a fault on an unfamiliar asset.
The BI dashboard flags assets where the same fault code appears more than twice in a configurable rolling window — surfacing repeat failure patterns automatically. Maintenance managers see the repeat failure list without running a manual query; each flagged asset links directly to the relevant work order history for investigation.
When an RCA produces a PM schedule change, the work order management workflow supports the creation of a linked PM update task from within the reactive work order close-out — the RCA finding and the resulting PM change are stored in the same asset record, creating a traceable before-and-after record. Cryotos customers who implement mandatory RCA close-out and link findings to PM updates consistently report a 35–50% reduction in reactive work order volume within 12 months.
A repeat failure is any breakdown on the same asset, caused by the same or closely related failure mode, that occurs more than once within a defined time window — typically 90 days. Repeat failures are distinguished from independent failures by the presence of an unresolved root cause: the first repair closed the symptom without addressing the systemic cause, allowing the same conditions to produce the same failure again.
The most common reason is that the maintenance process is designed to close work orders, not to solve problems. When technicians replace a failed component and close the work order without completing a root cause analysis, the failure cause remains. The asset runs until the same conditions reproduce the same failure — often within the same operating cycle as the original event. The repair was technically competent; the process was diagnostically incomplete.
Three changes are required. First, make root cause analysis mandatory at reactive work order close-out — not optional. Second, treat every repeat failure as a PM programme failure and investigate what the schedule is missing, not just what the component failed. Third, close the loop between RCA findings and PM schedule updates so that every RCA produces a specific, implemented maintenance programme change. Teams that implement all three consistently reduce their repeat failure rate by 40–60% within 12 months.
A CMMS with asset-level work order history, fault code tracking, and MTBF reporting is the essential tool. Run a monthly query on reactive work orders: flag any asset-fault code combination that appears more than twice in a rolling 90-day window. Track MTBF trends at the asset level quarter-over-quarter — a declining MTBF is an early indicator of an unresolved repeat failure cause. The 5 Whys methodology is the most effective root cause investigation technique for most mechanical repeat failures — it consistently traces apparent component failures back to the maintenance programme gaps that produced them.
Every repeat failure is a recoverable cost — a breakdown that was already paid for once and is now being paid for again. Cryotos gives maintenance teams the work order discipline, RCA enforcement, and asset failure history to identify repeat patterns early, investigate root causes systematically, and translate findings into PM programme improvements that prevent the next occurrence. Schedule a free demo to see how leading maintenance teams use Cryotos to break the fix-it-again cycle and convert repeat failure spend into planned, preventable maintenance.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











