
Downtime prevention is the set of proactive practices manufacturers use to keep equipment running, avoid unplanned stoppages, and protect production output. According to a McKinsey & Company analysis, unplanned downtime costs industrial manufacturers an estimated $50 billion annually - roughly $260,000 per hour in discrete manufacturing. For most plant managers, a single unexpected failure doesn't just halt one line; it ripples through scheduling, inventory, and customer commitments.
This guide breaks down the most effective downtime prevention strategies for manufacturers - from preventive maintenance schedules and predictive monitoring to root cause analysis and CMMS-powered workflows. Whether you manage a single facility or a multi-site operation, these methods will help you reduce unexpected failures and improve overall equipment effectiveness (OEE).
Downtime prevention is the deliberate effort to eliminate the conditions that cause equipment to stop unexpectedly. It's not just about fixing machines faster - it's about building systems, schedules, and habits that prevent failures from happening in the first place.
In manufacturing, downtime prevention covers three core areas: planned maintenance activities that keep equipment in good condition, monitoring systems that catch problems early, and operational processes that reduce human error and parts shortages. When all three work together, facilities consistently achieve availability rates above 90% - compared to the industry average of around 77%, per Plant Engineering's maintenance benchmarking study.
Understanding what kind of downtime you're dealing with shapes which prevention strategies you should prioritize.
Unplanned downtime happens without warning - a bearing seizes, a conveyor belt snaps, a sensor fails. This is the most damaging type because it disrupts production schedules and typically takes longer to resolve than planned stoppages.
Planned downtime includes scheduled maintenance windows, changeovers, and inspections. While it still stops production, it's controlled, budgeted, and doesn't disrupt customer commitments.
Micro-stoppages are short interruptions under 10 minutes - often unmeasured and uncounted - that collectively account for a significant share of lost capacity. A line with 15 micro-stoppages per shift at 3 minutes each loses 45 minutes of production daily without it ever appearing in a formal downtime report.
The goal of downtime prevention is to convert unplanned stoppages into planned ones, and planned ones into none at all.
Most manufacturers undercount the true cost of a stoppage because they only measure direct labor and materials. A full calculation includes lost production, delayed orders, overtime recovery costs, quality losses from restarting processes, and the ripple effects on customer relationships.
The ABI Research Industrial Manufacturing report puts the average hourly cost of unplanned downtime for a mid-size plant between $100,000 and $300,000 when all factors are included. For food and beverage or pharmaceutical manufacturers - where product must be discarded if a line stops mid-batch - the real cost is often much higher.
For a plant running two shifts at an average cost of $150,000 per hour, just 10 unplanned stoppages per year averaging 2 hours each equals $3 million in annual losses - losses that a well-run downtime prevention program can recover at a fraction of that cost.
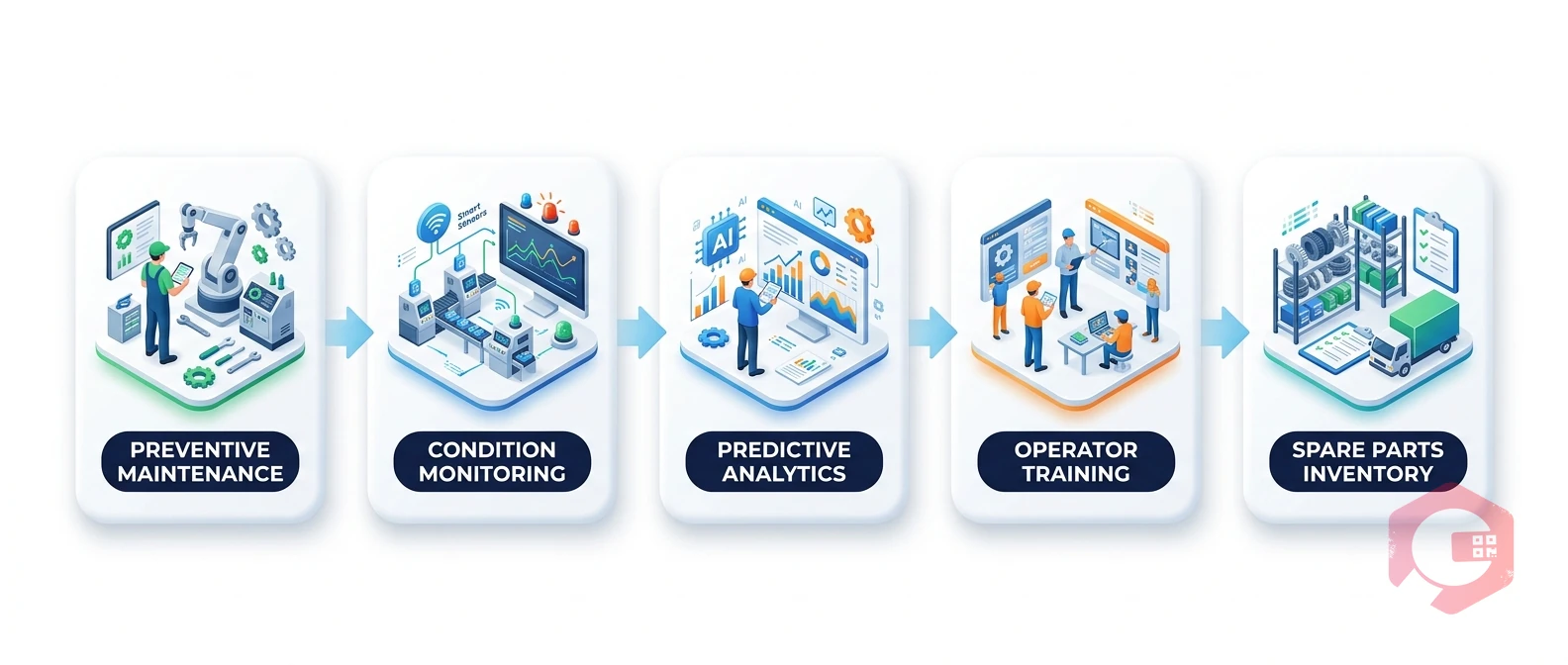
The seven strategies below build on each other. A preventive maintenance program is the foundation; predictive monitoring adds a layer of early warning; root cause analysis closes the feedback loop. Together, they form a complete downtime prevention system.
Preventive maintenance (PM) is the cornerstone of downtime prevention. It replaces the reactive "fix it when it breaks" approach with scheduled inspections, lubrication, cleaning, and part replacements at defined intervals - before failures can occur.
Start by auditing your current equipment list. Identify your top 20% of assets by criticality - the machines that, if they fail, stop an entire line. These get the most detailed PM schedules. Less critical assets get lighter inspection routines.
For each critical asset, define PM tasks at three levels:
One auto parts manufacturer in the Midwest restructured its PM program using this criticality-based approach and reduced unplanned failures on its top 15 machines by 62% in the first year - with no increase in maintenance labor headcount.
Static PMs trigger on fixed calendar intervals - every 30 days, every quarter. Dynamic PMs trigger based on usage - every 500 machine hours, every 10,000 cycles. Dynamic scheduling tends to be more accurate for high-utilization equipment because it ties maintenance to actual wear, not elapsed time.
Preventive maintenance prevents many failures, but it can't catch everything. Predictive maintenance (PdM) closes that gap by monitoring real-time equipment condition data - vibration, temperature, current draw, oil quality - and alerting your team when readings drift outside safe ranges.
The most common predictive maintenance techniques in manufacturing include:
Reliable Plant estimates that PdM typically reduces equipment failures by 25-30% compared to time-based PM alone.
You don't need to instrument every asset. Focus PdM investment on equipment where the cost of failure is high, the failure mode is detectable in advance, and lead time for parts is long. A compressor with a $50,000 repair cost and a 3-week lead time for a replacement motor is a strong predictive monitoring candidate. A $200 conveyor roller is not.
Every unplanned stoppage is a data point. If you only fix the symptom - replace the failed part and resume production - the same failure will happen again. Root cause analysis (RCA) identifies the underlying condition that allowed the failure to occur.
The most practical RCA method for manufacturing teams is the 5 Whys: ask "why did this happen?" five times in sequence until you reach the root cause rather than a symptom. Example: A CNC machine stops mid-cycle.
Root cause: An incomplete PM schedule. Fix: Add fan belt replacement to the PM task list with an 18-month interval. This single RCA prevents every future motor overheating event on that asset. The work order management module in Cryotos includes a built-in 5 Whys tool that lets technicians document root cause findings directly on the work order before closing it - making RCA a standard part of every repair, not an afterthought.
Even the best maintenance program can't prevent every failure. When something does break, the speed of repair depends heavily on whether the right parts are available. Many manufacturers lose 2-4 hours of repair time not to the repair itself, but to waiting for a part to arrive from a supplier or be located in a disorganized storeroom.
For each of your top critical assets, define a minimum on-hand quantity for parts that have a lead time over 48 hours and a history of failure. This list typically includes:
Set reorder points in your inventory system so that stock replenishment triggers automatically when you dip below the minimum. Cryotos Inventory Management provides real-time stock visibility with minimum threshold alerts, so your team gets notified before critical parts run out - not after a failure has already exposed the gap.
Your machine operators spend more time with your equipment than any maintenance technician does. They're the first people to hear an abnormal noise, feel unusual vibration, or notice that a machine is running slower than normal. Without structured training, these early warning signals often go unreported until a failure forces a stoppage.
Autonomous maintenance - a core pillar of Total Productive Maintenance (TPM) - trains operators to take ownership of basic equipment care: cleaning, lubrication, visual inspection, and abnormality reporting. This doesn't replace your maintenance team; it extends your early warning network to every shift, every day.
According to the OSHA Total Productive Maintenance guidance, facilities that implement autonomous maintenance programs consistently report 15-25% reductions in breakdowns within the first year of deployment. The key enabler is a clear, standardized abnormality reporting process so operators know exactly what to report and how.
A Computerized Maintenance Management System (CMMS) is the operational backbone of a downtime prevention program. Without it, PM schedules live in spreadsheets that get outdated, work orders get lost, and failure history never gets analyzed. With it, maintenance teams have a single system that schedules tasks, dispatches technicians, tracks parts, and records every failure for analysis.
A CMMS automates PM scheduling so tasks don't fall through the cracks - even when key staff are on leave. It records failure history against each asset so you can identify repeat failures and adjust maintenance frequency. It tracks mean time between failures (MTBF) and mean time to repair (MTTR) so you can benchmark improvement over time. And it provides a digital audit trail for compliance-sensitive facilities.
Cryotos customers who implement the full downtime tracking module typically see a 30% reduction in unplanned downtime within six months, and 25% faster repair times due to faster technician dispatch and parts lookup. The mobile app lets field technicians receive and close work orders from the floor without returning to a desktop - reducing response lag significantly.
You can't improve what you don't measure. Tracking the right metrics turns anecdotal complaints about downtime into actionable data your team can actually use.
The ISO 22400 standard for manufacturing operations management KPIs provides internationally recognized definitions for these metrics, which is helpful when benchmarking against industry standards or reporting to executive teams.
Use this checklist to assess the maturity of your downtime prevention program. Every "No" is an improvement opportunity.
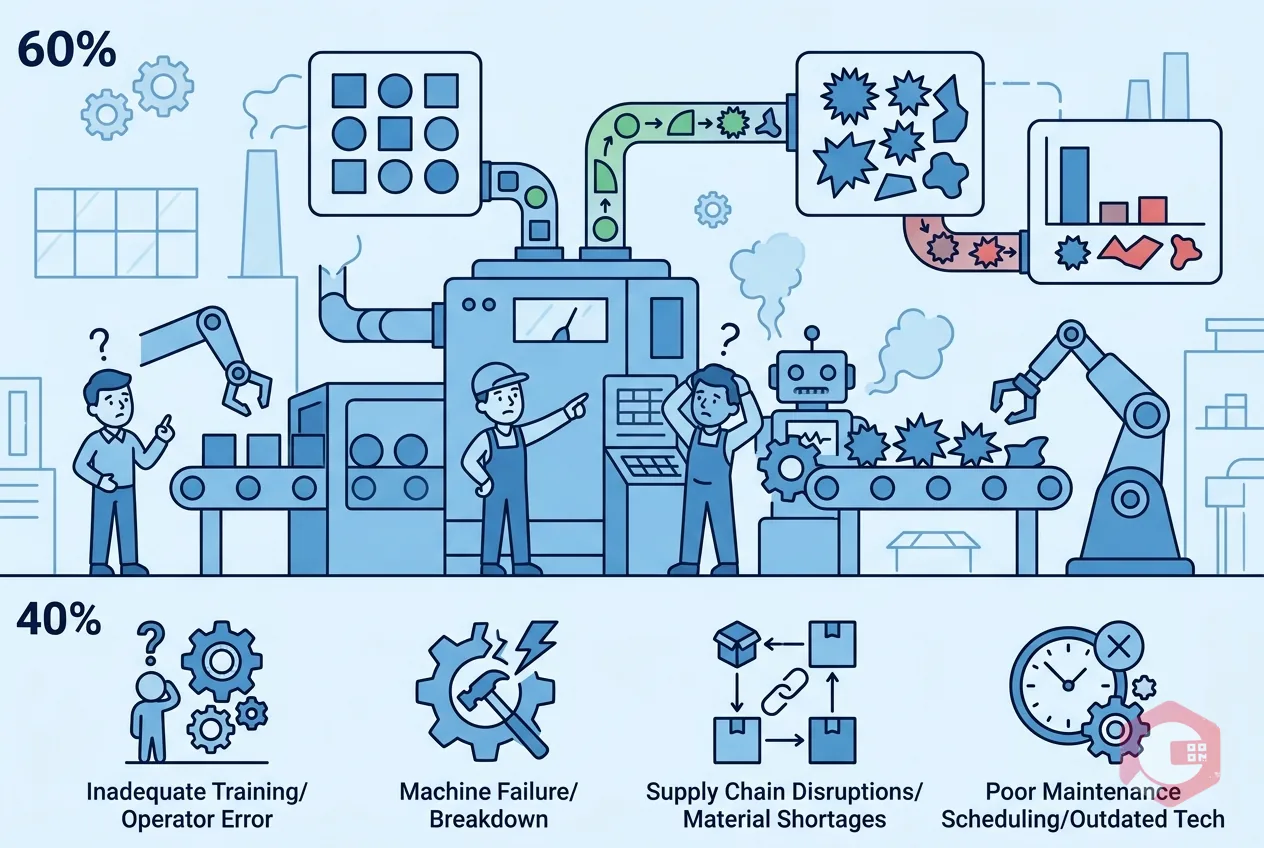
Equipment failure due to deferred or missed maintenance is the leading cause of unplanned downtime in most manufacturing environments. When PM tasks are skipped or delayed - often due to production pressure - wear accumulates until a component fails unexpectedly. The second most common cause is inadequate spare parts availability, which extends repair time even when the failure itself was minor.
Downtime prevention focuses on stopping failures from happening - through scheduled maintenance, predictive monitoring, and operator training. Downtime reduction focuses on recovering faster when stoppages do occur - through better parts availability, faster technician dispatch, and streamlined repair procedures. A complete maintenance strategy needs both: prevent what you can, and recover quickly from what you can't prevent.
A CMMS prevents downtime by automating PM scheduling so maintenance tasks never get missed, tracking asset failure history so patterns become visible, managing spare parts inventory to reduce repair delays, and providing real-time metrics like MTBF and MTTR for continuous improvement. It replaces the manual, spreadsheet-based approach that most plants start with - and quickly outgrow.
Facilities implementing structured downtime prevention programs for the first time - with a CMMS, improved PM scheduling, and basic root cause analysis - typically see 20-35% reductions in unplanned downtime within the first 12 months. The biggest early wins usually come from eliminating repeat failures through RCA and from getting PM completion rates above 90%.
Use a simple criticality matrix: score each asset on two dimensions - consequence of failure (how much production does it stop, and how long does it take to recover?) and probability of failure (how frequently does it break, based on history?). Assets that score high on both dimensions get your first attention and the most detailed PM and monitoring programs.
Preventing downtime in manufacturing isn't a single initiative - it's a system of layered practices that compound over time. Start with a strong preventive maintenance foundation, add predictive monitoring for your most critical assets, close every failure loop with root cause analysis, and use a CMMS to automate the entire workflow. Each step you take reduces the chance that an unexpected stoppage will disrupt your production schedule, your team, and your customers.
Cryotos CMMS gives manufacturing teams the tools to build and run this entire system in one place - from automated PM scheduling and mobile work orders to downtime tracking dashboards and built-in 5 Whys analysis. If you're ready to move from reactive firefighting to proactive control, explore Cryotos and see how our customers are cutting downtime by 30% or more.




Cryotos AI predicts failures, automates work orders, and simplifies maintenance—before problems slow you down.











